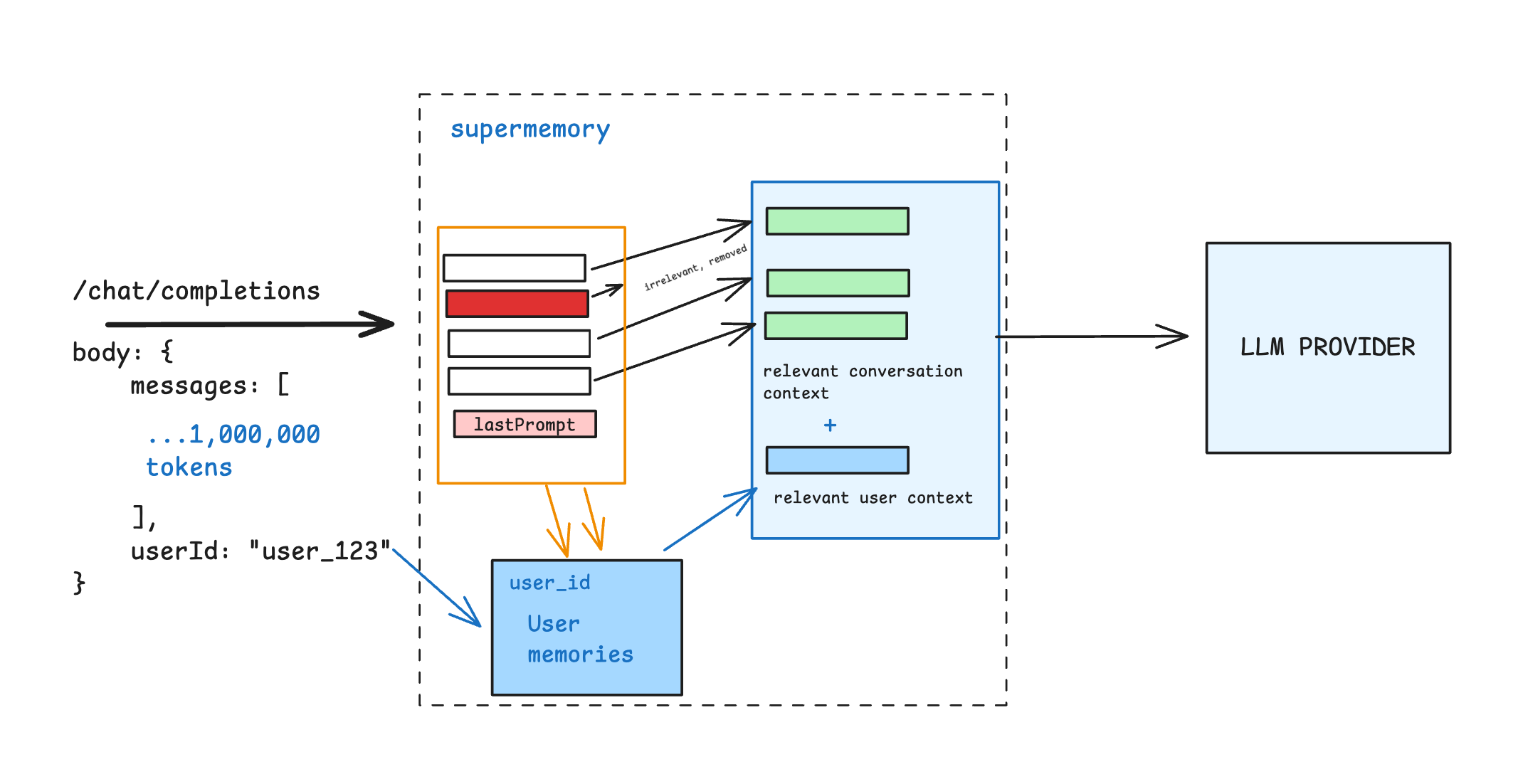
- No code refactoring - just swap the base URL with one provided by Supermemory. Read the quickstart to learn more.
- Better chatbot performance due to long-thread retrieval, when conversations go beyond the model window.
- Cost savings due to our automatic chunking and context management.
- Already have a working LLM chat and just want it to remember? Start with the Router.
- Building a new app or need strict tenancy, filters, ranking, or custom prompts? Go to the Memory API.
- Need both? Ingest via API, chat via Router; keep the user_id consistent.
- Still unsure? Pilot on the Router, then graduate parts of the flow to the API as you need more control.
FAQs
Is the Router just calling the Memory API behind the scenes?
Is the Router just calling the Memory API behind the scenes?
Conceptually, yes. The Router orchestrates the same Supermemory engine operations (retrieve, re-rank, budget, cite) and wraps them around your model call.
Does the Router store new memories automatically?
Does the Router store new memories automatically?
It can. The create-memory step is asynchronous, so the user’s response isn’t delayed.
What identifies the user’s memory across Router and API?
What identifies the user’s memory across Router and API?
user_id. Keep it consistent across Router and API calls to share the same memory pool.