Using Vercel AI SDK? Check out the AI SDK integration for the cleanest implementation with @supermemory/tools/ai-sdk. Prefer to run it locally? Supermemory is also a self-hostable single binary — curl -fsSL https://supermemory.ai/install | bash and you’re running. Memory API
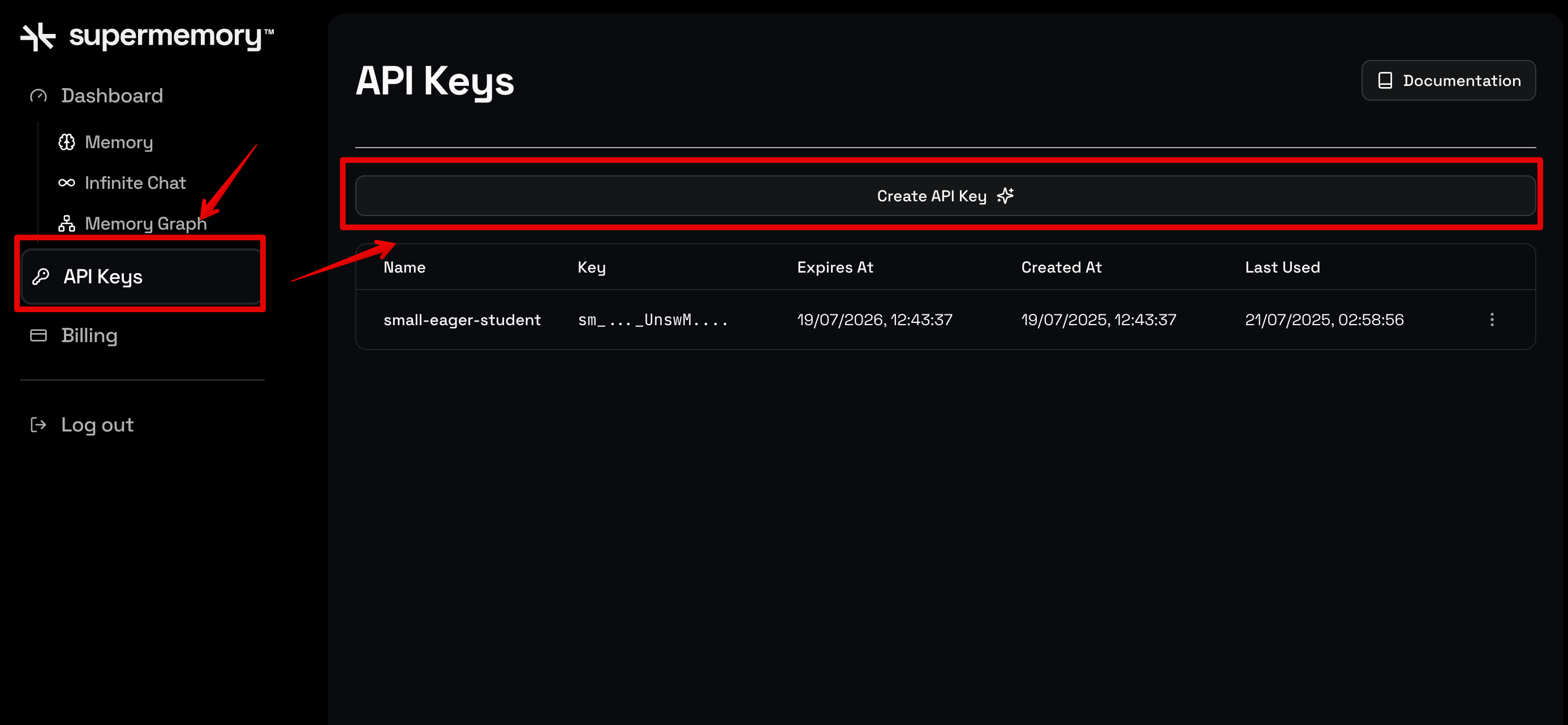
Step 1. Sign up for Supermemory’s Developer Platform to get the API key. Click on API Keys -> Create API Key to generate one.
 Step 2. Install the SDK and set your API key:
Step 3. Here’s everything you need to add memory to your LLM:
That’s it! Supermemory automatically:
Step 2. Install the SDK and set your API key:
Step 3. Here’s everything you need to add memory to your LLM:
That’s it! Supermemory automatically:
- Extracts memories from conversations
- Builds and maintains user profiles (static facts + dynamic context)
- Returns relevant context for personalized LLM responses
Optional: Use the threshold parameter to filter search results by relevance score. For example: client.profile(container_tag=USER_ID, threshold=0.7, q=query) will only include results with a score above 0.7.