How does it work? (at a glance)
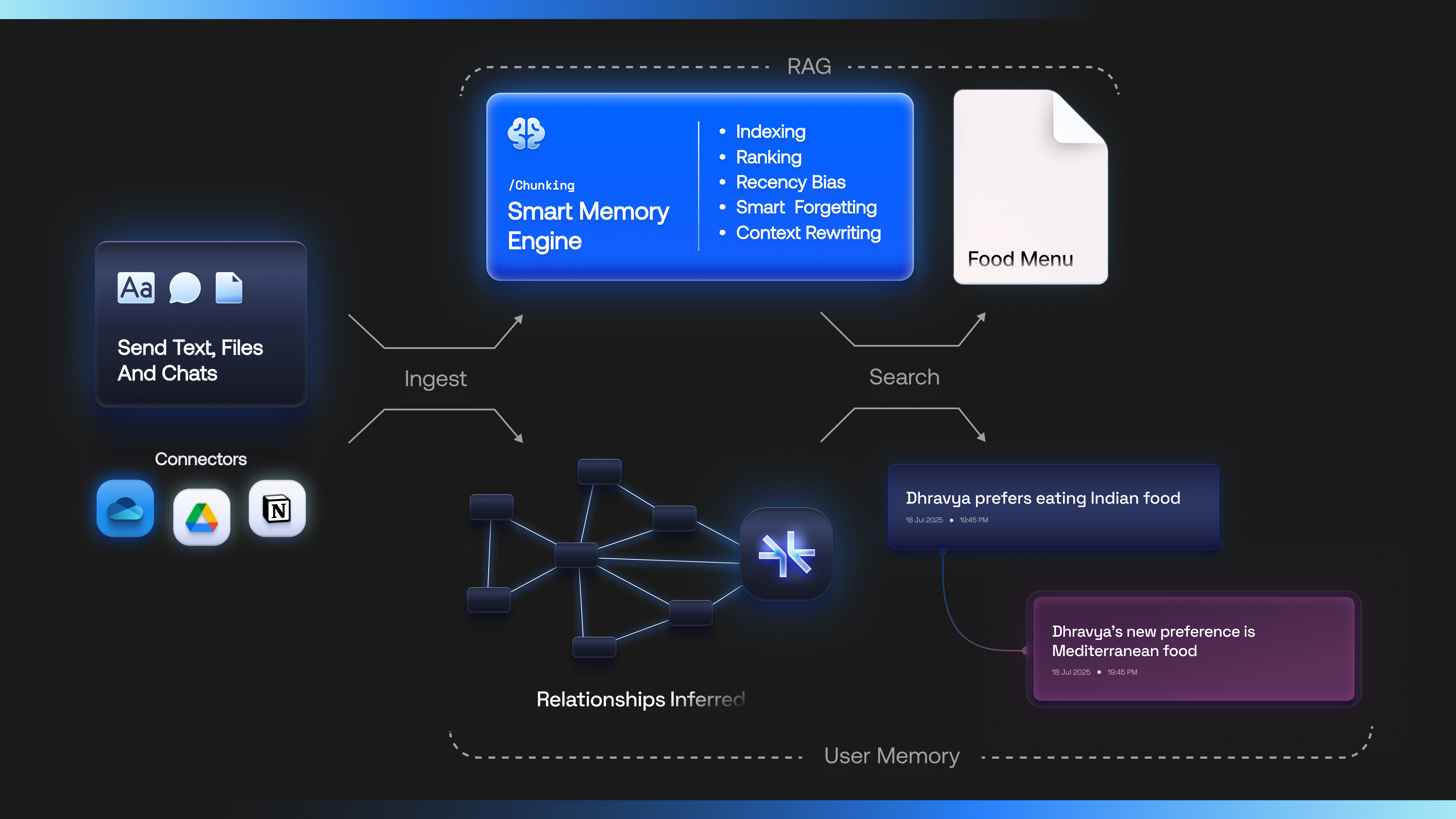
- You send Supermemory raw data in any format - text, files, and chats, or connect it to the data sources
- Supermemory intelligently indexes them using our user understanding model and builds a semantic understanding graph on top of an entity (e.g., a user, a document, a project, an organization). We call these entities
containerTag - This knowledge is now traversed by the agent, and an automatic profile is built for it. The agent may now use it for memory operations or for retrieval.
Why add memory to your agent?
Without memory, every session starts from zero. The model cannot know what the user preferred last week, which project they are on, or that a fact has changed since yesterday. Memory gives an agent durable understanding of people and entities over time — preferences, decisions, relationships, corrections. Retrieval (RAG) grounds answers in documents and knowledge bases. You usually want both. By adding memory to your agent, you can:- Personalize — remember preferences, roles, and history across sessions without stuffing the full chat log into every prompt
- Stay correct as facts change — “I love Adidas” then “switching to Puma” should not leave both preferences equally true
- Ground answers — pull the right policy, ticket, or doc when the question needs source material
- Ship multi-tenant products — isolate each user or workspace so one customer’s memory never leaks into another’s
Why Supermemory?
- State of the art on long-horizon memory — #1 on LongMemEval, LoCoMo, and ConvoMem, plus independent benches like SWEContext
- Memory is a graph, not a blob store — facts update, connect, and forget in real time; not nearest-neighbor chunks alone
- User profiles built in — static + dynamic context the agent should always know, ~ready for the prompt
- Memory + SuperRAG in one engine — personalize and ground on the same
containerTag/ context pool - Every door, one store — API, MCP, plugins, SMFS, connectors, and Company Brain share the same memories
- Multimodal by default — text, chats, PDFs, images, video, code via extractors and connectors
- Run it your way — managed cloud or self-host as a single binary (including offline)

Memory, profiles, and SuperRAG share the same context pool when you use the same isolation (
containerTag). Mix and match for your product! A container can be anything - a user, a project, team, organization, etc.Next steps
Quickstart
Make your first API call in minutes
How it Works
Understand the knowledge graph architecture
Comparison
vs DIY vectors, thin memory layers, pure RAG
Self-host it
One binary, zero config, fully offline
Billing & plans
Credits, SM tokens, and how usage works
Security & compliance
SOC 2, GDPR, HIPAA BAA, encryption