
Language is at the heart of intelligence, but what truly powers meaningful interaction is memory — the ability to accumulate, recall, and contextualize information over time. Large Language Models (LLMs) have mastered language, but memory remains their Achilles’ heel. Every leap in context window s
Language is at the heart of intelligence, but what truly powers meaningful interaction is memory — the ability to accumulate, recall, and contextualize information over time.
Large Language Models (LLMs) have mastered language, but memory remains their Achilles’ heel. Every leap in context window size is quickly outpaced by real-world demands: users upload massive documents, have lengthy conversations, and expect seamless recall of preferences and history. The result? LLMs that forget, hallucinate, and frustrate users to the point of wanting to just start over with a clean slate.
At Supermemory, the idea wasn’t always to help models remember better. It started off as a way to make *you* remember your bookmarks.
Then, it was a cost and accuracy efficient way to easily implement RAG in your product.
The more experience we had with this pain point, the more we were led to tackle context, and that’s what it currently stands as — a drop-in memory layer for your LLMs that is extremely scalable, with sub-400ms latency and enterprise-grade reliability.
Long context does not really solve this either - as found in popular papers and proven time and time again in real-world use-cases.
But why?
What Makes Memory for LLMs So Hard?
Building a memory layer for AI isn’t just about one more layer of data storage. You need to optimize for five uncompromising requirements:
- High Recall & Precision: Always surface the right information — even across years of chat history or thousands of documents, and filtering out irrelevant, outdated, or noisy data to keep responses accurate.
- Low Latency: Memory shouldn’t slow you down. It needs to work fast, especially at scale.
This is particularly a challenge - because all current solutions for memory are not built for scale.- Vector Databases: Either get too expensive, or too slow as they grow. There are new, proprietary, server-less options now - but we'll get into this shortly
- Graph: To add every node, or for every query, one typically has to traverse factors or magnitudes more edges than nodes.
- Key-value: The entire KV pair has to fit inside the context length of models. Which moves the problem from one context length to another.
- Ease of Integration: Developers need APIs and SDKs that require minimal changes to integrate — not weeks of onboarding or complex migrations.
Managing embeddings, migrating between them, doing research for new improvements, etc. is usually not the primary business goal for apps needing memory. Lots of engineering hours are wasted. - Semantic & Non-Literal Queries: Memory must understand nuances, metaphors, and ambiguity — not just literal matches. Humans don’t search against a corpus of data with search terms they kinda know.
What is "Non-literal match", here's an example

Most solutions optimize for some of these, but fall short on others — especially when it comes to semantic understanding and scaling to billions of data points - For example, a user asking questions about all their internet life may ask more “general” questions that require knowledge of the entire dataset, not just ability to fuzzy search keywords.
The Supermemory Approach: Human Memory at Scale
Your brain doesn't store everything perfectly as you see it—and that's actually a feature, not a bug. It forgets the mundane, emphasizes what you've used recently, and rewrites memories based on current context. Our architecture works the same way, but engineered for AI at scale.
Smart Forgetting & Decay
Just like you naturally forget where you parked three weeks ago but remember yesterday's important meeting, our system applies intelligent decay. Less relevant information gradually fades while important, frequently-accessed content stays sharp. No more drowning in irrelevant context.
Recency & Relevance Bias
That thing you just talked about? It gets priority. That document you reference constantly? It stays top-of-mind. We mirror your brain's natural tendency to surface what's actually useful right now, not just what's technically "relevant" to a search query.
Context Rewriting & Broad Connections
Your brain doesn't just file away facts—it rewrites them based on new experiences and draws unexpected connections. Our system does the same, continuously updating summaries and finding links between seemingly unrelated information. That random insight from last month might be exactly what you need for today's problem.
Hierarchical Memory Layers
Like how you have working memory, short-term memory, and long-term storage, we use Cloudflare's infrastructure to create memory layers that match how you actually think. Hot, recent stuff stays instantly accessible (we personally use KV). Deeper memories get retrieved when you need them, not before.
Building on top of the engine
Supermemory isn’t just another vector database or RAG toolkit. It’s a universal memory layer that gives your LLMs the power of infinite context, with near-instant plug-and-play integration. Add our endpoint to your existing AI provider, plug in your API key, and boom — you’re done.
On top of this engine, we've been building some interesting products and experiences -
- Memory as a service: Storing and querying multimodal data, at scale, with support for external connectors and sync with Google Drive, Notion, OneDrive, etc. It's a few API calls - just /add, /connect, /search https://docs.supermemory.ai/api-reference/manage-memories/add-memory
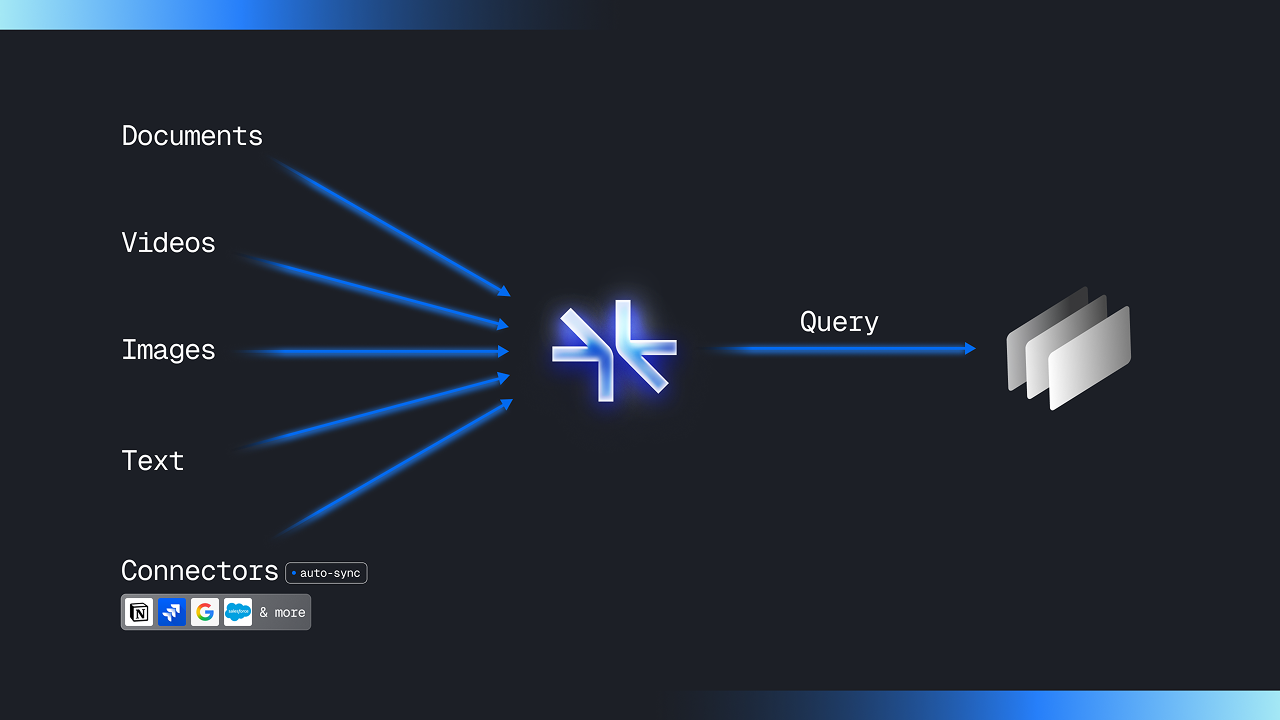
- The Supermemory MCP: Model-interoperable MCP server that lets users carry their memories, and chats, through LLM apps without losing context. This is actually built on top of our own Memory as a service
And our latest launch, called Infinite Chat API, manages memories inline with the conversation history to only send what's needed to the model providers. Leading to less token usage, cost savings, better latencies and better quality responses.
You heard that right. You can use it today with just one line of code!
We've been constantly improving this with our latest benchmarks, work and progress in the field.
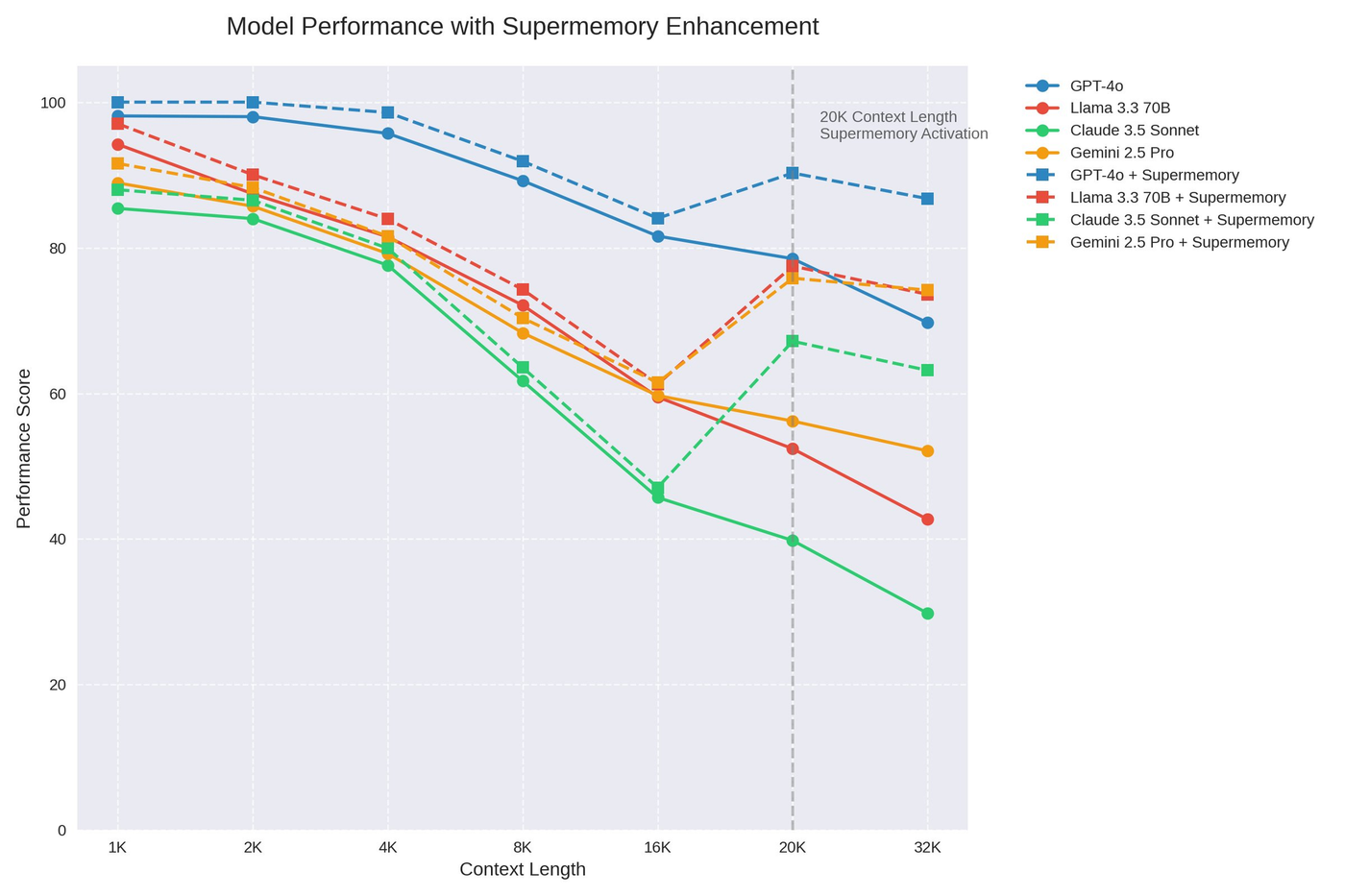
Memory is a huge missing piece on the road to AGI. With Supermemory, you can finally build products that remember, reason, and respond like never before.
If you believe in the mission, we're hiring. If you want better memory for your LLMs and apps - you can use all these products today. Check out our docs, MCP, and get an API key on our dashboard


