
Chatbots that don’t remember conversations are very frustrating to work with. Users treat AI like a human and expect it to remember. LangChain recently migrated to LangGraph, a new stateful framework for building multi-step, memory-aware LLM apps. So while the docs might still say “LangChain memory
Chatbots that don’t remember conversations are very frustrating to work with. Users treat AI like a human and expect it to remember.
LangChain recently migrated toLangGraph, a new stateful framework for building multi-step, memory-aware LLM apps. So while the docs might still say “LangChain memory,” what you’re actually using under the hood is LangGraph.
In this guide, we’ll walk through how to implement short-term conversational memory in LangChain using LangGraph.
We’ll build a real-world chatbot and compare the two core approaches to memory in LangGraph: message trimming and summarizing (more on them later). You’ll see how they differ, when to use what, and which one works best in a real use case.
Note: Here’s the link to the GitHub repo containing the code snippets used in the article.
But here's the reality: while these techniques work for demos and simple use cases, they quickly break down when you need reliable, scalable memory for real applications.
The Use Case: A Therapy Chatbot With Memory
To keep this practical, we’ll walk through a real-world example: a mental health chatbot. It’s the perfect use case to test memory, because:
- Conversations are long and personal
- Users often revisit old topics or emotions
- The bot needs to remember specific details like names, moods, and events
We’ll use the same conversation flow across all memory types, so we can compare how each performs. By the end, you’ll know exactly how to add memory to your LangChain app and which memory type makes the most sense for your use case.
Primer: What is Conversational Memory?
Conversational memory allows chatbots to remember the context of their conversation with the user and tailor their answers to new prompts accordingly for a more intelligent experience.
It’s basically meant to model how you’d talk to another person. Imagine trying to hold an hour-long conversation with someone who keeps forgetting everything you’ve said. Not fun, right?
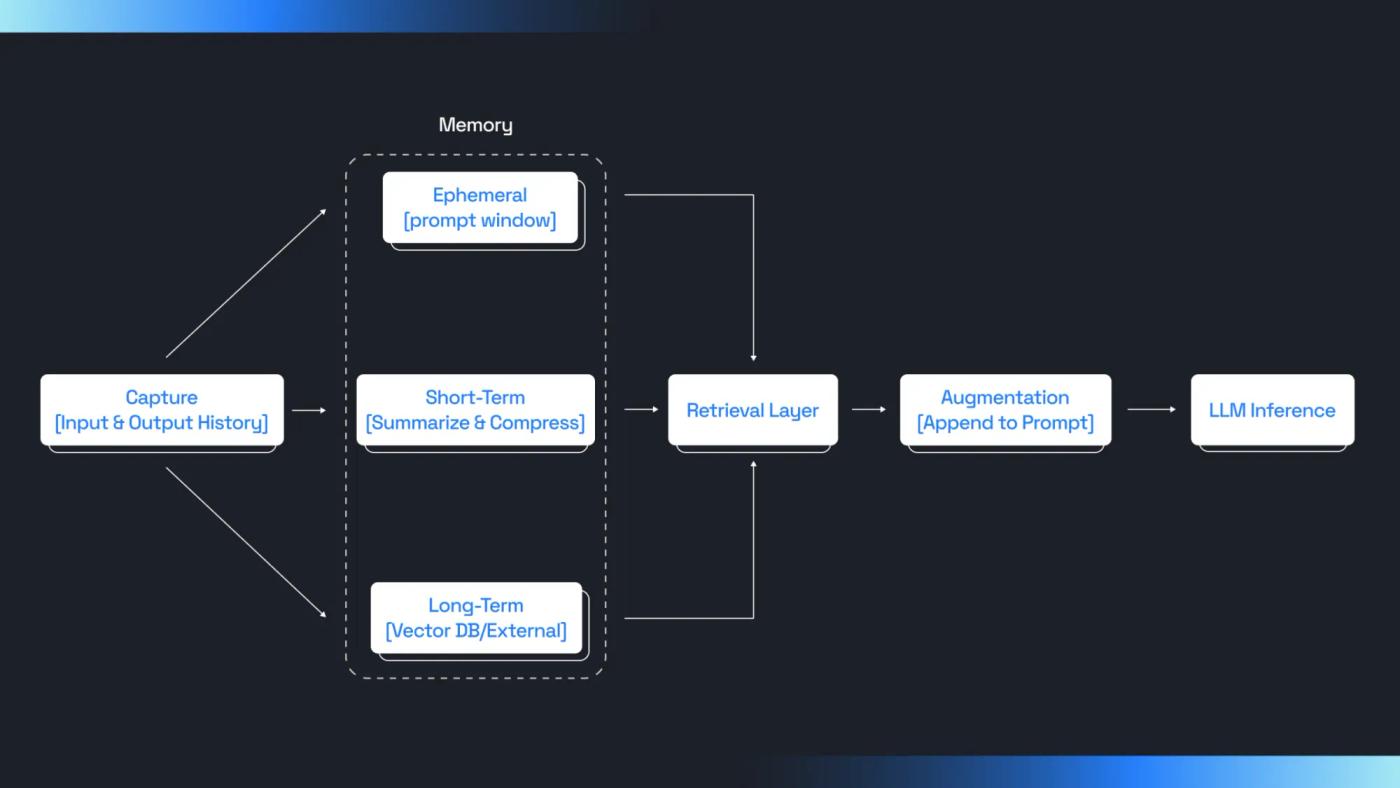
At an architectural level, memory in LLMs works like this:
- Input and Output History: Every user message and model response is captured.
- Memory Storage: That conversation history is either:
- stored in the prompt window (ephemeral),
- summarized and compressed (short-term memory), or
- persisted in a separate, retrievable vector DB or external memory (long-term memory).
- Retrieval Layer: At inference time, relevant pieces of past conversation are pulled in via raw replay, windowing, summarization, or vector similarity.
- Augmentation: That context is appended to the current prompt before sending to the LLM.
If we think of the most basic classification, then LLM memory can either be short-term or long-term. Here’s the difference:
Type
What It Does
How It’s Stored
When It’s Used
Short-term
Tracks the current conversation window
Prompt buffer, summarization
Most chatbot interactions
Long-term
Remembers facts and context across sessions
Vector store, DBs, JSON, etc.
Persistent user knowledge, histories
While this architecture is clever, it's still fundamentally limited. Managing threads manually becomes a nightmare at scale, and the memory patterns are too rigid for complex, evolving user relationships.
LangGraph Memory Architecture: Short-Term vs Long-Term
LangGraph introduces a new way of handling memory that’s far more powerful than the old ConversationBufferMemory-style classes you might be used to. It supports both short-term and long-term memory through state management and memory stores.
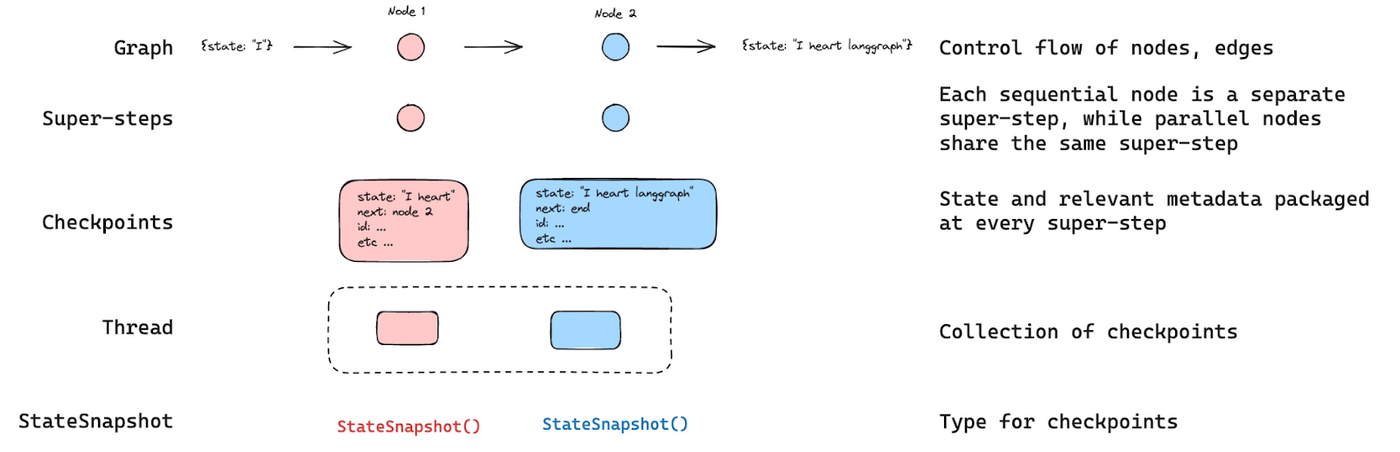
LangGraph has a built-in persistence layer that allows it to remember what’s going on. It has a few key concepts like state, threads, and checkpoints.
Think of building a chatbot with LangGraph as writing in a notebook. The state refers to the notebook page where you're recording the actual conversation: what’s been said, what tools were used, what decisions were made.
Every time something happens in your app, this state, or notebook page, gets updated with what happened.
Now, imagine that every user, or session, gets their own notebook. That’s what a thread is: an isolated session that stores several different states and has a unique ID to identify it.
If a user returns tomorrow, you just give LangGraph the same thread ID, and it picks up right where you left off, flipping back to the last used page.
Now, let’s say you want to bookmark key moments in your notebook so you can return to them. That’s what checkpoints are: a snapshot of the state at a specific time.
LangGraph automatically creates a checkpoint every time you invoke a graph with a thread ID.
How LangChain Implements Short-Term Memory
You basically store the conversation history in the state, usually as a list of messages. Each time a user sends a message or the LLM generates a response, it is appended to this list, which is the short-term memory of the LLM. You can also store documents, uploaded files, and other metadata in the graph’s state so that the LLM has access to the full context.
There are two main ways to maintain this list of messages:
- Message Buffering: Keeps the last k messages in memory
- Summarization: Replace older history with a summary
Now, we’ll implement these in code for our therapy chatbot.
Adding Conversational Memory To Our LLM
First, we’ll start by storing all the messages in our therapy chatbot’s context, and then we’ll move on to advanced techniques like message trimming and summarizing.
Basic Setup
Let’s start with the setup first. Create a directory for the chatbot and open it in your IDE:
mkdir memory-chatbot
Install all the necessary Python libraries:
pip install --upgrade --quiet langchain langchain-openai langgraph
Note: Use pip3 in case just pip doesn’t work.
Basic Memory
Let’s start building the chatbot. Create a file.py file in your folder and import the necessary libraries:
from langchain_openai import ChatOpenAI
from langchain.schema import SystemMessage, HumanMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START, MessagesState
import os
You’ll start by setting your OpenAI API key as an environment variable. Navigate to your memory-chatbot folder and run the following command in the terminal to set the environment variable:
export OPENAI_API_KEY=”YOUR_API_KEY”
Here are the steps to find your OpenAI API key.
Back to file.py. Retrieve the environment variable:
os.environ.get("OPENAI_API_KEY")
Now, initialize your model:
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
The next step while building an LLM with LangGraph is to initialize the graph that represents the workflow that gets carried out. Here’s how:
builder = StateGraph(state_schema=MessagesState)
Since the chatbot stores the chat history, this code defines MessagesState as the schema, which means the state contains a list of messages.
Now, if you think about it, graphs contain nodes that carry out the actual logic. Our main logic is going to be the chatbot that acts like a therapist, asks questions, generates responses, and stores them in its memory.
Thus, we’ll now define a function that carries out this logic as follows:
def chat_node(state: MessagesState):
system_message = SystemMessage(content="You're a kind therapy assistant.")
history = state["messages"]
prompt = [system_message] + history
response = model.invoke(prompt)
return {"messages": response}
The node is passed the state, which is the chat history. Prompts to LLMs contain a system instruction (developer instructions on how the LLM must behave) and a human message.
The code instructs the LLM to act as a therapy assistant, and our prompt contains both the system message and the complete list of messages since we’re passing the entire context to it. This prompt is sent to OpenAI, which returns a response.
Let’s add this node to our graph and define it as the start node as follows:
builder.add_node("chat", chat_node)
builder.add_edge(START, "chat")
Next, write the following:
memory = MemorySaver()
chat_app = builder.compile(checkpointer=memory)
The MemorySaver() stores the state in memory, and the builder.compile compiles and executes the graph with the memory checkpointer.
If you go back to our breakdown of LangChain’s architecture, you’ll remember that LangChain used a unique thread identifier to set a unique ID for each conversation and store its memory separately. Declare that in your code:
thread_id = "1"
Finally, let’s allow the user to enter messages and update our app’s state accordingly with the following code:
while True:
user_input = input("You: ")
state_update = {"messages": [HumanMessage(content=user_input)]}
result = chat_app.invoke(
state_update,
{"configurable": {"thread_id": thread_id}}
)
print(result)
ai_msg = result["messages"][-1]
print("Bot:", ai_msg.content)
This code takes the user input, wraps it in the HumanMessage class, and appends the list of messages stored. After that, the graph is invoked with chat_app.invoke. The result is then printed.
Upon executing the code, we get the following results:
You: Hi I'm John from San Francisco
Bot: Hi John! It's nice to meet you. How are you doing today?
You : I'm doing okay, but I need some help managing my anxiety.Bot: I’m glad you reached out, John. Managing anxiety can be challenging, but there are strategies that can help. Can you share a bit more about what specifically triggers your anxiety or how it manifests for you?
If we print the actual messages response, then we notice the following after the bot’s first response:
{'messages': [HumanMessage(content="Hi I'm John from San Francisco",...), AIMessage(content="Hi John! It's nice to meet you. How are you doing today?", …), HumanMessage(content="I'm doing okay, but I need some help managing my anxiety.", …), AIMessage(content='I’m glad you reached out, John. Managing anxiety can be challenging, but there are strategies that can help. Can you share a bit more about what specifically triggers your anxiety or how it manifests for you?', …)]}
What you can notice is that the messages key contains all the chats. The bot maintains a memory by storing all the previous chats and responding to new questions accordingly. Every time a question is asked, this entire list of messages is sent as part of the prompt.
This approach is pretty simple and gives us a workable chatbot, but it has some severe drawbacks. LangGraph replays all the messages stored in memory for every new message, and the full system prompt + message history is sent to the LLM as input.
LLMs have a finite token limit. Eventually, the prompt becomes too large to fit into the model’s context window, which leads to a shit ton of errors.
On top of that, more tokens = more cost = higher OpenAI bills. Our therapy chatbot would have long conversations, so that would become super expensive, super fast. Lastly, token-heavy prompts would also degrade performance.
That’s where the next approach comes in: message trimming.
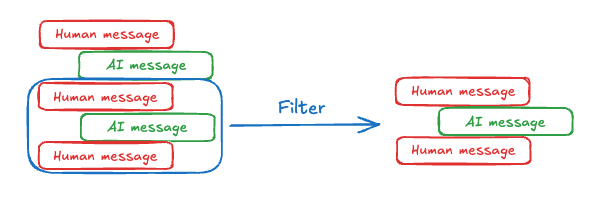
Memory With Message Trimming
Message trimming only stores a certain k number of messages in the memory, which prevents memory overload, stays within token limits, and focuses only on recent context.
To implement it, create a new file trimmed.py and add the following code to it:
from langchain_openai import ChatOpenAI
from langchain.schema import SystemMessage, HumanMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START, MessagesState
from langchain_core.messages import trim_messages
import os
os.environ.get("OPENAI_API_KEY")
# Initialize model
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
trimmer = trim_messages(strategy="last", max_tokens=2, token_counter=len)
# Create the graph
builder = StateGraph(state_schema=MessagesState)
def chat_node(state: MessagesState):
trimmed_messages = trimmer.invoke(state["messages"])
system_message = SystemMessage(content="You're a kind therapy assistant.")
prompt = [system_message] + trimmed_messages
response = model.invoke(prompt)
return {"messages": response}
builder.add_node("chat", chat_node)
builder.add_edge(START, "chat")
# Compile graph with MemorySaver
memory = MemorySaver()
chat_app = builder.compile(checkpointer=memory)
thread_id = "2"
while True:
user_input = input("You: ")
state_update = {"messages": [HumanMessage(content=user_input)]}
result = chat_app.invoke(
state_update,
{"configurable": {"thread_id": thread_id}}
)
print(result)
ai_msg = result["messages"][-1]
print("Bot:", ai_msg.content)
You’ll notice most of this is the same as the previous file. Except, now we’re importing the trim_messages function:
from langchain_core.messages import trim_messages
And, we’re declaring a trimmer at the beginning of our code:
trimmer = trim_messages(strategy="last", max_tokens=10, token_counter=len)
This trimmer counts every message as 1 token, and only keeps the last 10 tokens (5 pairs of human + AI conversation).
The chat_node function has also been edited:
def chat_node(state: MessagesState):
trimmed_messages = trimmer.invoke(state["messages"])
system_message = SystemMessage(content="You're a kind therapy assistant.")
prompt = [system_message] + trimmed_messages
response = model.invoke(prompt)
return {"messages": response}
First, the messages are trimmed by invoking the trimmer on the current state, and then those trimmed messages are passed to the prompt. Thus, the entire state is not passed, saving tokens.
Now, if we replay our previous conversation, it goes as follows:
You: hi im john from sf
Bot: Hi John! It's nice to meet you. How are you doing today?
You: im doing okay, you?
Bot: I’m glad to hear you’re doing okay! I’m here and ready to help with anything you need. Is there something specific on your mind today?
You: yeah dealing with some general anxiety
Bot: I’m sorry to hear that you’re feeling anxious. It’s completely normal to experience anxiety from time to time. Would you like to talk about what’s been causing your anxiety, or would you prefer some tips on managing it?
You: idk whats causing it - stressed about work i think
Bot: That makes sense. Work-related stress can definitely contribute to feelings of anxiety. It might help to break down what aspects of work are causing you stress. Is it the workload, deadlines, interactions with colleagues, or something else? Sometimes identifying specific triggers can make it easier to manage those feelings.
You: yeah i think it's a mix of them all
Bot: That sounds really overwhelming. It’s tough when multiple factors contribute to stress. Have you had a chance to take breaks or practice any self-care during busy times? Even small moments of relaxation can help alleviate some of that anxiety.
You: yeah i guess that makes sense. i should take a break right?
Bot: Absolutely! Taking a break can be really beneficial. It gives your mind a chance to reset and can help reduce feelings of anxiety. Even a short walk, some deep breathing exercises, or just stepping away from your workspace for a few minutes can make a difference. What do you think you might do for your break?
You: what's my name?
Bot: I’m sorry, but I don’t have access to personal information like your name unless you share it with me. If you’d like to tell me your name or anything else, feel free!
As you can see, when I ask the what’s my name question, the previous 5 memories don’t contain it, thus the chatbot forgets. It’s an improvement over the basic model, but it still has drawbacks:
- Trimming may lead to loss of crucial context, which is not a part of the last 10 tokens.
- Trimming isn’t intelligent, so there’s an arbitrary information cutoff.
- Even with trimming, token creep might happen if the input/output is extremely long.
The next approach, summarization of old context, builds upon these.
Memory With Summarization
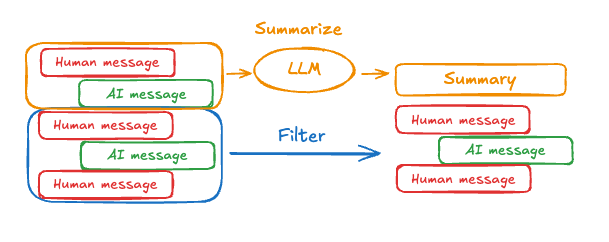
Summarization allows the LLM to summarize all conversations before the current one, thus reducing token usage while also ensuring minimal context loss.
Create a new file summarized.py and write the following code in it:
from langchain_openai import ChatOpenAI
from langchain.schema import SystemMessage, HumanMessage
from langchain_core.messages import RemoveMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START, MessagesState
import os
os.environ.get("OPENAI_API_KEY")
# Initialize model
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Create graph
builder = StateGraph(state_schema=MessagesState)
def chat_node(state: MessagesState):
system_message = SystemMessage(content="You're a kind therapy assistant.")
history = state["messages"][:-1]
if len(history) >= 8:
last_human_message = state["messages"][-1]
summary_prompt = (
"Distill the above chat messages into a single summary message. "
"Include as many specific details as you can."
)
summary_message = model.invoke(history + [HumanMessage(content=summary_prompt)])
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"]]
human_message = HumanMessage(content=last_human_message.content)
response = model.invoke([system_message, summary_message, human_message])
message_updates = [summary_message, human_message, response] + delete_messages
else:
message_updates = model.invoke([system_message] + state["messages"])
return {"messages": message_updates}
builder.add_node("chat", chat_node)
builder.add_edge(START, "chat")
# Compile graph with MemorySaver
memory = MemorySaver()
chat_app = builder.compile(checkpointer=memory)
thread_id = "3"
while True:
user_input = input("You: ")
state_update = {"messages": [HumanMessage(content=user_input)]}
result = chat_app.invoke(
state_update,
{"configurable": {"thread_id": thread_id}}
)
print(result)
ai_msg = result["messages"][-1]
print("Bot:", ai_msg.content)
This has some more significant changes. Firstly, you’re importing the RemoveMessages function, which wasn’t there previously.
In terms of logic, there are changes in the chat_node function. The summarization logic only kicks in when the total conversation has gone over 8 messages.
If that happens, first the history is retrieved, except the latest HumanMessage, which is why we’ve used the [:-1] operator. Then, the model is invoked with a prompt to summarize the content, and the history variable is passed along with the instructions.
After that, all the summarized messages are removed from the state to save on tokens. The latest human message is wrapped again inside the HumanMessage() class, and then the model is invoked again with the summary and the human message, but this time with the therapy chatbot system message.
Finally, the model response is returned with the new information.
If the history is less than 8 messages, then normal conversation chaining is used. This makes the chatbot efficient for shorter chats as well.
Upon running some test instructions, the following is seen:
You: hi im jack from sf
Bot: Hi Jack! It's nice to meet you. How are you doing today?
You: im okay, wbu?
Bot: I’m doing well, thank you! I’m here to help you with anything you need. Is there something specific on your mind today?
You: just a bit of general anxiety
Bot: I’m sorry to hear that you’re feeling anxious. It’s completely normal to experience anxiety from time to time. Would you like to talk about what’s been causing your anxiety, or would you prefer some tips on how to manage it?
You: probably work is causing it
Bot: Work can definitely be a significant source of stress and anxiety. Would you like to share more about what aspects of work are making you feel anxious? Sometimes just talking about it can help.
You: yeah i think it's about how fast the deadlines are now
Bot: It sounds like the pressure of tight deadlines is really weighing on you. That can definitely contribute to feelings of anxiety. Would you like to talk about what specific aspects of the deadlines are causing you the most stress? Sometimes breaking it down can help us find ways to manage it better.
The conversation flows as normal, however if you look at the full message output, after the 8 messages, we receive the following output in the console:
{'messages': [AIMessage(content='**Jack from San Francisco mentioned he was feeling okay but experiencing some general anxiety, which he attributed to work-related stress. He expressed a desire to discuss the causes of his anxiety or seek tips for managing it.**',...), HumanMessage(content="yeah i think it's about how fast the deadlines are now",...), AIMessage(content='It sounds like the pressure of tight deadlines is really weighing on you. That can definitely contribute to feelings of anxiety. Would you like to talk about what specific aspects of the deadlines are causing you the most stress? Sometimes breaking it down can help us find ways to manage it better.', …)]}
As you’ll see, everything else from before was summarized, while the two latest messages are stored in memory. This is the best approach we’ve explored until now, but as always, there’s always room for improvement.
You see:
- Summaries are only as good as the prompt + model, so the quality’s a bit unreliable.
- Hard deletes can be risky. If the summarization is off, you’ve lost the original data.
Evaluating both the techniques
For evaluation of the trimming and summarizing chatbots, we created 6 generic questions/responses we’d pass into the chatbots to see how they’d perform. We’re also measuring them across 6 quantitative metrics:
Metric
Description
Scoring (0–1)
Notes
Fact Retention
Mentions or uses previous facts correctly (name, job, etc.)
1 = correct use; 0 = wrong/missing
-
Entity Count
Number of correctly named entities reused
0 to worse chatbot; 1 to the better one. If tied, 1 to both.
Proxy for detail richness
Latency / Turn Depth
How far back memory is used (e.g., Turn 1 fact used in Turn 6)
0 -1
Higher is better
Token Usage
Total tokens used in the conversation
0 - 1
Counted via OpenAI or LangSmith tools
Response Length
Average word/token count per AI reply
0 -1
Spot unnecessarily long answers
Repetition Penalty
Counts of repeated generic phrases
-1 or 0
Penalize fluff like “I understand how you feel.”
Our 6 prompts are as follows:
- “Hi, I’m John. I’ve been feeling overwhelmed lately.”
- “It started after I got promoted to product manager..”
- “I usually go for a run in the morning, but I’ve stopped doing that recently.”
- “My therapist told me to start journaling, but I haven’t.”
- “Also, I had a fight with my brother Jack yesterday.”
- “Can you help me make a plan to feel more in control again?”
Trimming (set at 8 tokens)
You: “Hi, I’m John. I’ve been feeling overwhelmed lately.”
Bot: Hi John, it’s great to meet you. I’m really sorry to hear that you’ve been feeling overwhelmed. Would you like to share a bit more about what’s been going on? Sometimes talking about it can help.
You: “It started after I got promoted to product manager..”
Bot: That sounds like a big change, John. Congratulations on your promotion! It’s understandable to feel overwhelmed with new responsibilities. What aspects of your new role are feeling particularly challenging for you?
You: “I usually go for a run in the morning, but I’ve stopped doing that recently.”
Bot: It sounds like running has been an important part of your routine. Exercise can be a great way to manage stress and clear your mind. What do you think has made it difficult for you to keep up with your morning runs lately?
You: “My therapist told me to start journaling, but I haven’t.”
Bot: It’s okay, John. Starting something new like journaling can be tough, especially when you’re feeling overwhelmed. Sometimes it helps to set small, manageable goals. Would you be open to trying just a few minutes of journaling each day, or even just jotting down a few thoughts when you feel up to it? It can be a great way to process your feelings.
You: “Also, I had a fight with my brother Jack yesterday.”
Bot: I’m sorry to hear that, John. Conflicts with family can be really tough to navigate. Would you like to talk about what happened with Jack? Sometimes discussing the situation can help you find some clarity or a way to approach it.
You: “Can you help me make a plan to feel more in control again?”
Bot: Absolutely, John. It’s great that you want to take steps to feel more in control. Here’s a simple plan we can start with:
1. **Set Small Goals**: Choose one or two small, achievable goals each week. For example, you might aim to go for a short run a couple of times or write in your journal for just five minutes.
2. **Establish a Routine**: Try to create a daily routine that includes time for exercise, journaling, and some relaxation. Consistency can help you feel more grounded.
3. **Communicate with Jack**: If you feel ready, consider reaching out to your brother to talk about the fight. A calm conversation can help clear the air and strengthen your relationship.
4. **Practice Mindfulness**: Incorporate a few minutes of mindfulness or deep breathing into your day. This can help reduce stress and bring you back to the present moment.
5. **Reflect Weekly**: At the end of each week, take a moment to reflect on what went well and what you might want to adjust for the following week.
How does that sound to you? Would you like to modify any part of this plan?
Tokens used: 1.618K completion tokens
Summarizing (set at 8 messages)
Here’s how it responded:
You: “Hi, I’m John. I’ve been feeling overwhelmed lately.”
Bot: Hi John, it’s nice to meet you. I’m really glad you reached out. Feeling overwhelmed can be tough to deal with. Would you like to share more about what’s been on your mind or what’s been making you feel this way?
You: “It started after I got promoted to product manager..”
Bot: That sounds like a significant change, John. Congratulations on your promotion! It’s understandable to feel overwhelmed with new responsibilities. What aspects of your new role are feeling particularly challenging for you?
You: “I usually go for a run in the morning, but I’ve stopped doing that recently.”
Bot: It sounds like running was an important part of your routine and a way for you to manage stress. It’s common for changes in our lives, like a new job, to disrupt our usual habits. How do you feel about not being able to run lately? Do you think getting back to it might help you feel a bit better?
You: “My therapist told me to start journaling, but I haven’t.”
Bot: Journaling can be a really helpful tool for processing your thoughts and feelings, but it can be hard to get started, especially when you’re feeling overwhelmed. It’s okay if you haven’t begun yet. Maybe you could start with just a few minutes a day or even jot down a few thoughts when you feel inspired. What do you think might help you get started with journaling?
You: “Also, I had a fight with my brother Jack yesterday.”
Bot: I'm sorry to hear that you had a fight with your brother, Jack. Conflicts with loved ones can be really tough to navigate. How are you feeling about the situation? Do you want to talk about what happened? Sometimes expressing your thoughts and feelings can help you process the experience.
You: “Can you help me make a plan to feel more in control again?”
Bot: Absolutely, I’d be happy to help you create a plan to feel more in control. Here’s a simple outline you can follow:
1. **Reintroduce Morning Runs:**
- **Set a Schedule:** Choose specific days and times for your runs. Start with two or three days a week.
- **Start Small:** If you’re feeling overwhelmed, begin with shorter runs or even brisk walks to ease back into it.
2. **Begin Journaling:**
- **Set Aside Time:** Dedicate a few minutes each day, perhaps in the morning or before bed, to write down your thoughts and feelings.
- **Prompts:** If you’re unsure what to write about, consider prompts like “What am I grateful for today?” or “What challenges did I face, and how did I handle them?”
3. **Address the Conflict with Jack:**
- **Reflect:** Take some time to think about what led to the fight and how you feel about it.
- **Communicate:** When you feel ready, consider reaching out to Jack to talk about what happened. Express your feelings and listen to his perspective.
4. **Practice Mindfulness:**
- **Breathing Exercises:** Incorporate deep breathing or meditation into your daily routine to help manage stress.
- **Mindful Moments:** Take a few moments throughout the day to check in with yourself and acknowledge your feelings.
5. **Set Realistic Goals:**
- **Daily Goals:** Identify one or two small goals each day that can help you feel accomplished, whether it’s going for a run, journaling, or reaching out to a friend.
6. **Seek Support:**
- **Talk to Someone:** Whether it’s a friend, family member, or therapist, sharing your feelings can provide relief and perspective.
How does this plan sound to you? Would you like to adjust anything or add more specific details?
Tokens used: 1,940 tokens
Evaluation:
Metric
Description
Trimming
Summarization
Notes
Fact Retention
Correct recall/use of facts from earlier turns
1
1
Both bots correctly referenced all six facts (John, promotion, running, journaling, Jack, and feeling overwhelmed).
Entity Count
Number of correctly named entities reused
1
1
Both mentioned John, Jack, running, journaling, etc. Summarization didn’t sacrifice detail.
Latency / Turn Depth
How far back a memory is reused (e.g., Turn 1 info in Turn 6)
0
1
Summarization reused context from all 5 previous turns in the final response, trimming lost older context earlier.
Token Usage
Total tokens used
1
0
Trimming uses fewer tokens due to shorter prompts and hard message cuts; summarization adds summarizer calls and more verbose responses.
Avg. Response Length
Average length of bot replies
1
0
Trimming’s responses are shorter, while summarization is more verbose; it can be less desirable for token-sensitive applications.
Repetition Penalty
Penalty for repeated generic phrases (lower = better)
-1
0
Trimming led to more generic fallback lines (“That’s understandable.”); summarization preserved specificity despite verbosity.
Final scores are 3-3 for both models, tied. While both trimming and summarization scored equally in our evaluation, the tie doesn’t imply that the two strategies are interchangeable.
Trimming excels in token economy and snappy responses. It’s simple, lightweight, and great for short or transactional conversations. But once the dialogue gets deeper or longer, it starts forgetting context, leading to generic or disconnected replies, which earns it a repetition penalty.
Summarization, on the other hand, maintains coherent long-form memory. It preserves emotional and factual continuity over time, allowing for more natural conversations. But this comes at a cost: higher token usage and longer responses, which might not be ideal for production environments with strict token budgets.
Supermemory
With Supermemory, you can add memory with just one line of code.
import OpenAI from "openai"
const client = new OpenAI({
baseUrl: "https://api.supermemory.ai/v3/https://api.openai.com/v1/"
}, {
headers: {
"x-supermemory-user-id": "dhravya"
}
})That's it.
Supermemory automatically ingests and manages the context, using a combination of Graphs and Vector store. Read more about it in this blog - https://supermemory.ai/blog/memory-engine/
Conclusion
This article covered everything from how conversational memory works to implementing it in LangChain, using both trimming and summarizing, and then evaluating them for their particular use cases.
However, it starts to fall apart as complexity grows. If you're building apps and AI agents that need to remember across sessions, adapt to users, or scale without manual patchwork, Supermemory's Memory API might be a better solution for you. Check it out here.


