
You’ve already met our guide on implementing short-term conversational memory using LangChain, which is great for managing context inside a single chat window. But life, therapy, and enterprise apps sprawl across days, weeks, and years. If our agents are doomed to goldfish-brain amnesia, users end
You’ve already met our guide on implementing short-term conversational memory using LangChain, which is great for managing context inside a single chat window.
But life, therapy, and enterprise apps sprawl across days, weeks, and years. If our agents are doomed to goldfish-brain amnesia, users end up re-explaining everything from their favorite color to yesterday’s heartbreak.
It's time to graduate from sticky notes to an external brain. This guide will show you what long-term memory in LLMs really is and how to implement it using multiple techniques, like in-memory stores in LangChain, vector databases, Supermemory, etc.
Why Long-Term Memory Matters
Relying on raw token history means stuffing ever-growing chat logs back into each prompt. That quickly blows past context windows, hikes latency and cost, and still buries the signal beneath filler:
- No prioritization. The model wastes attention on greetings while forgetting allergies or project deadlines
- Brittle reasoning. Events like “last Friday’s outage” can’t be referenced without replaying the whole week
- Repetitive answers. The agent re-derives stable traits (“prefers metric units”) every turn
Real-world apps need selective, structured, semantically indexed data points—facts, timelines, preferences, insights gleaned from analysis, just to skim the top.
Selecting, pruning, and handing these nuggets to a language model keeps prompts lean, token counts reasonable, and replies coherent across browser tabs and chat threads.
Therapy Assistant, Short-Term Context Edition
In part one, we built a therapy assistant that remembers within a session via trimming or summarizing. Close the tab or start a new chat session, however, and it’s obvious the bot needs some therapy of its own.
- Personal details vanish, and users must retell their story
- No cross-thread recall. Parallel chats never share insights
- Token bloat. Replaying the whole transcript balloons prompts
In short, we need long-term memory.
Goal
Augment our therapy assistant with long-term, structured memory so sessions feel like genuine continuity. Users should see smooth recall of names, milestones, and coping strategies, plus tighter, more context-aware suggestions because the bot can finally connect the dots between Monday’s panic and Friday’s breakthrough.
We’ll layer in hybrid storage: JSON for crisp facts, a vector database for nuance, and a lightweight retrieval loop that feeds only the relevant slices back to the model.
Persistent Memory: The LangGraph Approach
LangGraph has built-in persistence to support long-term LLM memory using states, threads, and checkpointers. For short-term memory, LangGraph stores the list of messages to the chatbot in the state. Using threads, you can uniquely identify which user session the particular memory belongs to. Refer to our short-term memory guide for a full breakdown of how these work.
However, this memory cannot be shared across threads or across user sessions. For that, LangGraph implements something called stores.
A Store can well, store information as JSON documents across threads and make it available to the graph at any particular point, across different user sessions. Information is organized using namespaces, which basically are folders, but if you want to get technical, they are tuples that are used to uniquely identify a set of memories. Here's an example declaration:
user_id = "1"
namespace_for_memory = (user_id, "memories")
Memory stores are basically like databases managed by LangGraph. Hopefully, this diagram helps you visualize how stores work:
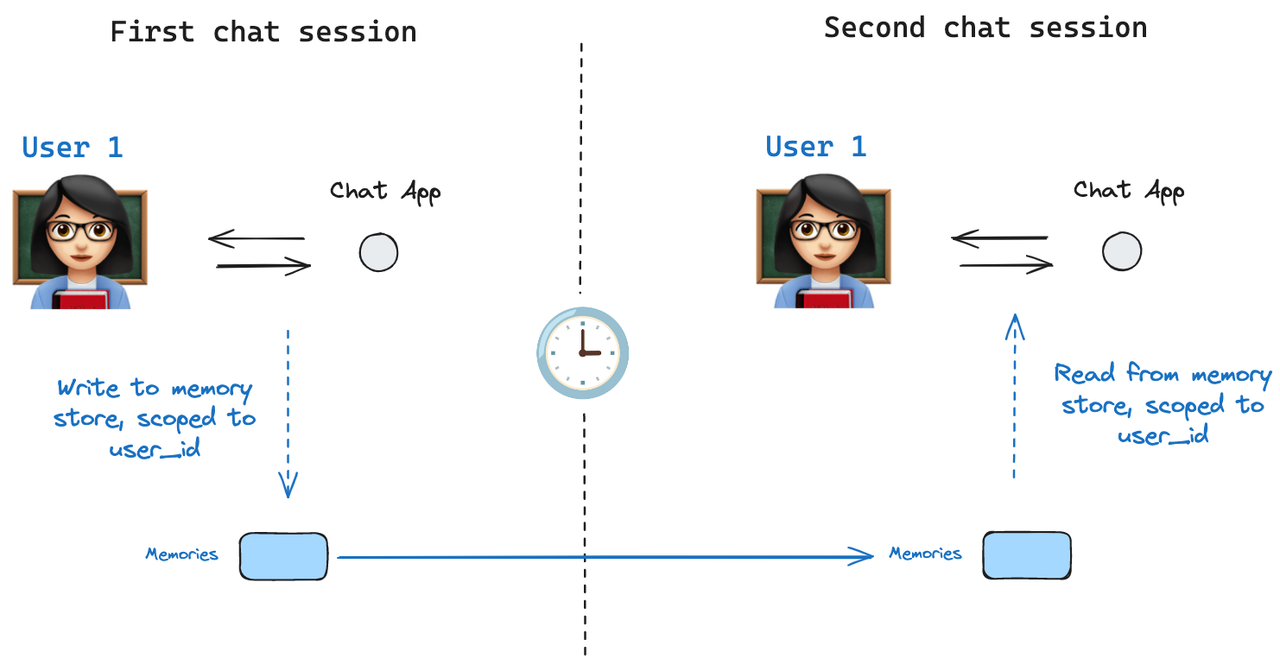
Every time our therapy agent receives a message, we hydrate working memory with just the bits that matter.
Building the Persistent Therapy Bot
Let's start building our therapy chatbot, and then extend it with persistent memory. We'll start by using the code for the chatbot from our previous tutorial.
Setup
Create a directory for the chatbot and open it in your IDE:
mkdir memory-chatbot
Install all the necessary Python libraries:
pip install --upgrade --quiet langchain langchain-openai langgraph
Note: Use pip3 in case just pip doesn’t work.
Basic Conversational Chatbot
Create a file file.py, and start with the following imports:
from langchain.schema import HumanMessage, SystemMessage
from langchain_core.messages import RemoveMessage, trim_messages
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, MessagesState, StateGraph
Set your OpenAI API key as an environment variable by running the following in your terminal:
export OPENAI_API_KEY=”YOUR_API_KEY”
Back to the Python file. Import the API key with:
os.environ.get("OPENAI_API_KEY")
Awesome! LangGraph uses graphs to represent and execute workflows. Each graph contains nodes, which are the individual steps or logic blocks that get executed. Create a function to represent that as follows:
def build_summarized(model: ChatOpenAI, trigger_len: int = 8) -> StateGraph:
builder = StateGraph(state_schema=MessagesState)
def chat_node(state: MessagesState):
system = SystemMessage(content="You're a kind therapy assistant.")
summary_prompt = (
"Distill the above chat messages into a single summary message. "
"Include as many specific details as you can."
)
if len(state["messages"]) >= trigger_len:
history = state["messages"][:-1]
last_user = state["messages"][-1]
summary_msg = model.invoke(history + [HumanMessage(content=summary_prompt)])
deletions = [RemoveMessage(id=m.id) for m in state["messages"]]
human_msg = HumanMessage(content=last_user.content)
response = model.invoke([system, summary_msg, human_msg])
message_updates = [summary_msg, human_msg, response] + deletions
else:
response = model.invoke([system] + state["messages"])
message_updates = response
return {"messages": message_updates}
builder.add_node("chat", chat_node)
builder.add_edge(START, "chat")
return builder
Let's break this function down. The build_summarized function takes in a model and a trigger_len variable as input. The model is the LLM that'll be used under the hood. We'll touch on the trigger_len variable in a second.
The graph is initialized in the builder variable, and the chat_node function represents the chatbot's node in the graph. It takes the state as an argument, which contains a list of messages stored by the chatbot.
The chat_node function summarizes the conversation history if it passes a certain length, which is what the trigger_len variable expresses. Only the recent message history is stored in memory, and the rest is deleted.
Using an interactive CLI, we'll stitch it together so you can talk to the chatbot:
def interactive_chat(build_graph, thread_id: str):
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
graph = build_graph(model)
chat_app = graph.compile(checkpointer=MemorySaver())
while True:
try:
user_input = input("You: ")
except (EOFError, KeyboardInterrupt):
print("\nExiting.")
break
state_update = {"messages": [HumanMessage(content=user_input)]}
result = chat_app.invoke(
state_update, {"configurable": {"thread_id": thread_id}}
)
print("Bot:", result["messages"][-1].content)
And:
if __name__ == "__main__":
interactive_chat(build_summarized, thread_id="demo")
MemorySaver keeps threads alive, thread_id lets you spawn parallel sessions. Right now, our chatbot doesn't have any persistent memory. This is just the basic implementation of a chatbot that you can actually talk to, and that can store the memory for individual sessions.
Memory Types for Human-like Interactions
Before we extend our chatbot with persistent memory, let's understand how effective memory mirrors human cognition:
- Semantic (Facts): Zara's birthday is September 14th
- Episodic (Events): Zara went through a breakup in May
- Procedural (Steps and Habits): Zara uses breathing exercises when anxious
Memory Types Mapped to Therapy
Memory kind
Therapy analogue
Example
Semantic
Stable facts
“Name is Zara”
Episodic
Lived events
“Broke up in May”
Procedural
Coping steps
“Box breathing on bad days”
Designing the Memory Schema
Field
Example
Purpose
facts
{ "name": "Zara", "birthday": "1995-09-14" }
Rapport, grounding
traits
["anxious_on_mondays", "prefers_metric"]
Tone adaptation
events
[{"date": "2025-05-01", "text": "Break-up"}]
Temporal reasoning
embeddings
Vector IDs pointing to free-text chunks
Nuanced recall
Implementing Persistent Memory in LLMs
There’s no single best way to implement long-term memory. As always, it boils down to your individual needs; however, we will go over three approaches that you can use.
In-Memory Store
InMemoryStore() is one of the types of memory stores that LangGraph provides for implementing persistent LLM memory. Let's write some code and demonstrate how it works. Create a new file long-term.py and import the necessary libraries and environment variables as follows:
import os
import uuid
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, MessagesState, StateGraph
from langgraph.store.memory import InMemoryStore
from langgraph.store.base import BaseStore
from langchain_core.runnables.config import RunnableConfig
from langchain.embeddings import init_embeddings
os.environ.get("OPENAI_API_KEY")
Initialize the model:
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
Let's build the graph:
builder = StateGraph(state_schema=MessagesState)
We'll have two nodes this time: update_memory to analyze user messages, find facts, and store them, and chat to retrieve the facts and respond.
Create the update_memory node as follows:
def update_memory(state: MessagesState, config: RunnableConfig, store: BaseStore):
user_id = config["configurable"]["user_id"]
namespace = (user_id, "memories")
last_message = state["messages"][-1]
analyze_prompt = (
"Analyze the last message and extract any facts that can be stored. "
"If there are no facts, return an empty string."
)
# Ask the model to summarize facts
analyze_msg = model.invoke([last_message] + [HumanMessage(content=analyze_prompt)])
memory_content = analyze_msg.content.strip()
memory_id = str(uuid.uuid4()) # Unique ID for this memory entry
store.put(
namespace=namespace,
key=memory_id,
value={"facts": memory_content},
index=["facts"] # This enables semantic search over 'facts'
)
The state, config, and store have been passed as arguments. The user_id is retrieved and used to point to the correct namespace.
The user's last message is analyzed using another LLM prompt and the facts are stored and put in the memory store using the store.put() function.
We're also using semantic search in this code on the facts field, thus is has been passed in the index so that it can be embedded. Semantic search allows us to retrieve the right memories using natural questions. For instance, memory about the user's favorite food can be retrieved even with a question like 'What do I like eating?'.
Great, now, let's move on to the chat node:
def chat_node(state: MessagesState, config: RunnableConfig, store: BaseStore):
user_id = config["configurable"]["user_id"]
namespace = (user_id, "memories")
# Fetch up to 3 memories that are similar to the user's current message
memories = store.search(
namespace=namespace,
query=state["messages"][-1].content,
limit=3
)
# Convert memory objects to a usable string
info = "\n".join([d.value["facts"] for d in memories])
system = SystemMessage(content=f"You're a kind therapy assistant. Here's any past memory: {info}")
# Respond based on memory + user input
response = model.invoke([system, state["messages"][-1]])
return {"messages": [response]}
This node takes the latest user query and searches the store to retrieve any memories matching that query. The retrieved memories are fed to the LLM as a part of the system prompt, and an appropriate response is generated. Next, the nodes are added to the graph and connected:
builder.add_node("update_memory", update_memory)
builder.add_node("chat", chat_node)
builder.add_edge(START, "update_memory")
builder.add_edge("update_memory", "chat")
Finally, the memory checkpointer and the store are actually declared, and the graph gets compiled:
memory = MemorySaver()
inmemstore = InMemoryStore(
index={
"embed": init_embeddings("openai:text-embedding-3-small"),
"dims": 1536,
"fields": ["facts"]
}
)
chat_app = builder.compile(
checkpointer=memory,
store=inmemstore
)
An embedding function is used to convert the user's input into vector data that can be searched and retrieved using natural language queries.
Now, let's test this chatbot:
input_messages = {"messages": [
HumanMessage(content="Hello, I am Jack from SF. I love pizzas with olives and bell peppers.")
]}
config = {"configurable": {"thread_id": "3", "user_id": "1"}}
for chunk in chat_app.stream(input_messages, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
input_messages = {"messages": [
HumanMessage(content="Thinking of making one actually. What favorite toppings should I use?")
]}
config = {"configurable": {"thread_id": "6", "user_id": "1"}}
for chunk in chat_app.stream(input_messages, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
The above code runs two separate conversations across different thread IDs (3 and 6), still the chatbot can remember and retrieve the accurate information as seen in the output:
================================ Human Message =================================
Hello, I am Jack from SF. I love pizzas they re my favorite with olives and bell pepper as my favorite toppings.
================================== Ai Message ==================================
Hi Jack! It’s great to meet you! Pizza is such a delicious choice, especially with olives and bell peppers. Do you have a favorite place in San Francisco to get your pizza, or do you enjoy making it at home?
================================ Human Message =================================
Thinking of making one actually. What favorite toppings should I use?
================================== Ai Message ==================================
Since you mentioned that Jack enjoys olives and bell peppers on his pizza, those would be great toppings to consider! You could also think about adding some cheese, pepperoni, or mushrooms for extra flavor. What do you think?
Voila! The in-memory store works! However, there's one big issue - it can't be used in production environments without hooking it up to a vector/Postgres database.
Vector Database
That's where our next approach comes in: a vector database. It'll allow us to not only persist data across sessions in production-grade apps, but also make it very easy to scale. There are a lot of vector DBs you can choose from for LLM memory, but in this tutorial ,we'll be using Chroma.
Install it:
pip3 install chromadb
This time, our therapy chatbot will have both long-term memory with Chroma and short-term memory with summarizing. Do the necessary imports first:
import os
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
from langchain_core.messages import RemoveMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START, MessagesState
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables.config import RunnableConfig
os.environ.get("OPENAI_API_KEY")
After that, initialize the model and vector database and create the graph:
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
embedding_model = OpenAIEmbeddings(model="text-embedding-3-small")
vector_db = Chroma(collection_name="therapy_longterm", embedding_function=embedding_model, persist_directory="./chroma_langchain_db")
builder = StateGraph(state_schema=MessagesState)
An embedding model is necessary to convert the textual data into vector embeddings that can later be searched. We declare a Chroma database by creating a collection, which is basically like a folder containing all your embeddings, documents, etc. A persistent directory stores the data locally.
Now, the first step would be to create a node that stores the appropriate memory for Chroma:
def store_facts_to_chroma(state: MessagesState, config: RunnableConfig):
user_id = config["configurable"]["user_id"]
last_msg = state["messages"][-1]
extract_prompt = HumanMessage(content="Extract any specific facts from the user's last message. If none, return nothing.")
extracted = model.invoke([last_msg, extract_prompt]).content.strip()
if extracted:
vector_db.add_texts([extracted], metadatas=[{"user": user_id}])
This function retrieves the user_id and the user's last message. Using another LLM prompt, any specific facts are extracted and then added to the vector database using the add_texts() function, which is specifically used to convert textual data into embeddings and store it. The metadata stores additional data about an embedding which can be used to filter data during retrieval.
We'll associate every embedding with a particular user so that we can retrieve it later.
Now, let's create a chat node that combines both short-term + long-term memory as follows:
def chat_node(state: MessagesState, config: RunnableConfig):
user_id = config["configurable"]["user_id"]
last_input = state["messages"][-1]
history = state["messages"][:-1]
# Retrieve relevant long-term memory
retrieved = vector_db.similarity_search_with_score(
last_input.content,
k=3,
filter={"user": user_id}
)
long_term_context = "\n".join([doc.page_content for doc, _ in retrieved])
# Add relevant facts to system prompt
system_message = SystemMessage(
content=f"You're a kind therapy assistant. Here are past facts you may find useful:\n{long_term_context}"
)
if len(history) >= 8:
# Summarize history and trim
summary_prompt = HumanMessage(content="Distill the above chat messages into a single summary message. Include as many specific details as you can.")
summary_message = model.invoke(history + [summary_prompt])
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"]]
response = model.invoke([system_message, summary_message, last_input])
message_updates = [summary_message, last_input, response] + delete_messages
else:
response = model.invoke([system_message] + state["messages"])
message_updates = response
return {"messages": message_updates}
This function first retrieves the relevant long-term memory to answer a user's question using a similarity search. This context is passed to the system prompt. On top of that, a conversational history of recent messages is also maintained, which leads to efficient answering and retrieval. Messages more than 8 tokens old are summarized.
Finally, the nodes are added to the graph, and everything is linked and stitched together as follows:
builder.add_node("store_facts", store_facts_to_chroma)
builder.add_node("chat", chat_node)
builder.add_edge(START, "store_facts")
builder.add_edge("store_facts", "chat")
# Compile graph with short-term memory (MemorySaver)
memory = MemorySaver()
chat_app = builder.compile(checkpointer=memory)
# Run interactive loop
if __name__ == "__main__":
thread_id = "8"
user_id = "user-44"
while True:
try:
user_input = input("You: ")
except (EOFError, KeyboardInterrupt):
print("\nExiting.")
break
state_update = {"messages": [HumanMessage(content=user_input)]}
config = {"configurable": {"thread_id": thread_id, "user_id": user_id}}
result = chat_app.invoke(state_update, config)
ai_msg = result["messages"][-1]
print("Bot:", ai_msg.content)
Let's see the results of this. First, I ran a conversation and gave the model some facts:

After that, I closed that session, started a new one, and asked it questions referencing my previous chat:
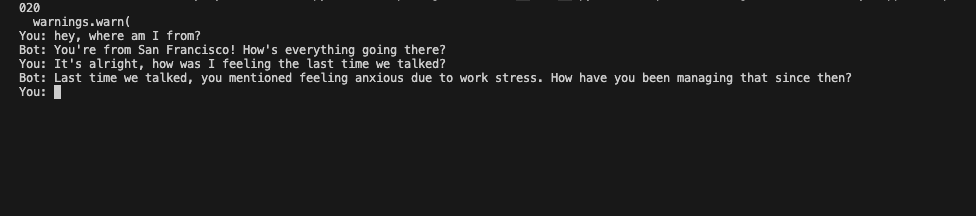
And the chatbot successfully remembers!
There are a couple of other techniques you could use, like JSON stores and knowledge graphs, and we'll quickly touch on them.
JSON Store
Use a JSON store if you’re just getting started or storing a few fixed keys per user (like name, location, preferences).
Pros
- Dead simple. No dependencies or setup. Great for prototyping.
- You can open the file, see what went wrong, and fix it manually.
- Works well with Git. You can diff and audit changes easily.
Cons
- Doesn’t scale. Disk I/O slows down fast once you have more than a few users.
- No search. You can’t ask “what did the user say about their brother last week?” without scanning everything.
- Schema changes are annoying. You’ll need migration logic if field names change.
Knowledge Graph (Advanced)
This is basically memory with structure. Nodes (e.g., people, events, feelings) and edges (e.g., “talked to”, “felt about”) let you model complex relationships over time. Use it if you're building something domain-heavy like medical, legal, or diagnostic agents.
Pros
- Great for long timelines and causal reasoning.
- Makes the bot explainable. You can trace why it said something.
- Queries can get surgical. Ask “How often has John mentioned his mom after fights?”
Cons
- Setup is heavy. You’ll need to choose a graph DB, define your schema, and build an ETL process.
- Total overkill for simple use cases.
- Learning curve. Graph thinking is its own skill.
Each system forgets in its own way: JSON forgets structure, graphs forget boundaries, vectors forget order. The trick is choosing one whose blind spots won’t trip your app.
Start with the simplest thing that won’t sabotage you. If responses feel slow or clueless, that’s your cue to mutate: shard JSON, add vectors, or graduate to a graph.
Supermemory: Super Simple Persistence
Building bespoke persistence in LangGraph teaches you the plumbing. Most days, though, you just want the sink to work.
Supermemory bolts in with a few lines. Quickly install it from your command line:
pip3 install supermemory
Declare a client with your API key:
import supermemory
client = supermemory(
api_key="YOUR_API_KEY",
)
Now, easily add memories:
client.memory.create(
customId="id1",
content="documents related to python",
metadata={
"category": "datascience",
"tag_1": "ai",
"tag_2": "machine-learning",
},
containerTags=["user_123", "project_xyz"]
)
You can assign IDs, metadata, tags, etc. And retrieving is super simple as well:
client.search.execute(
q="machine learning concepts",
limit=10
)
You can use NLP, and with automatic chunking, the retrieval is one of the fastest in the entire industry.
Apart from that, Supermemory offers multimodal search, sub-second retrieval, and a model-agnostic proxy that stretches context windows indefinitely!
Conclusion
Awesome, your chatbots now have long-term memory as well. Now, take it to the next level by keeping a tight feedback loop: log prompts and retrievals, review mismatches, prune stale memories, and refactor schemas regularly. Keep a tab on the context and don’t be sentimental about deleting what no longer serves.
Nail that, and a clear, relevant memory stack will turn your ordinary LLMs into extraordinary ones. However, LangGraph's solutions, like in-memory stores and traditional vector databases, start breaking at scale. That is where Supermemory's simple, yet infinitely scalable system comes in - test how easy it is to get started today.


