





New
Dynamic dreaming is now default
The context cloud
The context cloud
for agents.
Supermemory gives your agents state-of-the-art memory, RAG, user profiles, connectors, and extractors, all built in. Extremely low latency. Works with any model.
〉PRODUCT CATALOG
[1/9]
All the legos to build the perfect context for your agent.
Focused primitives for ingesting, understanding, routing, and retrieving context.






01 · MEMORY
Memory & Continual Learning
State-of-the-art memory that is persistent, structured, and built as a knowledge graph using our custom user understanding model, powered by dynamic dreaming and a custom graph engine.
〉WHAT WE DO
[2/9]
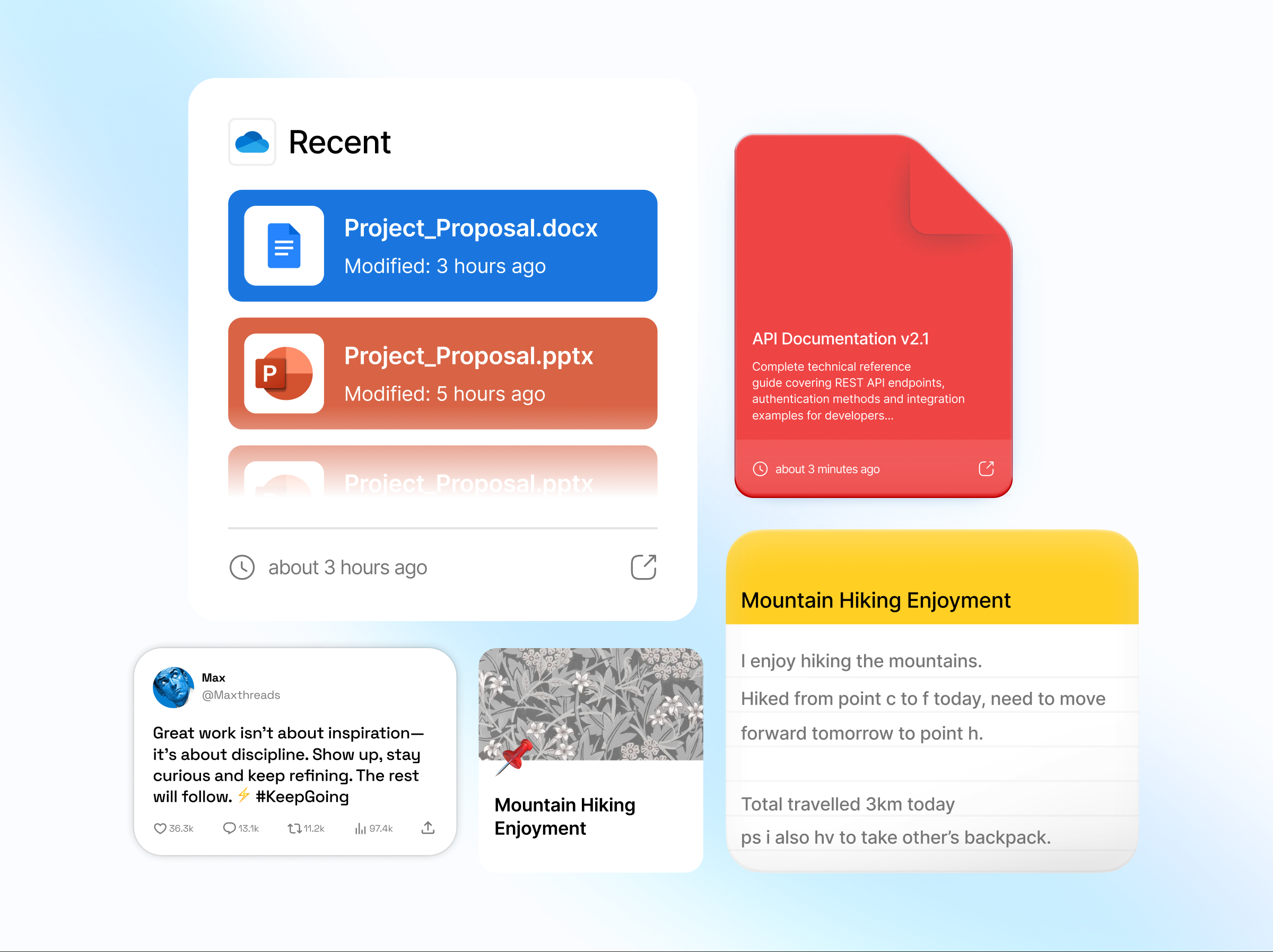
Bring your data We build understanding. Your agent just knows.
Context infrastructure for AI agents. One API, every capability.
For developers & teams
The Supermemory API
State-of-the-art retrieval and memory. RAG, memory, and extraction. One API, every capability.
<300ms Recall latency
100B+ Tokens / month
#1 On every bench
Self-hostable · SOC 2 Type II · TypeScript & Python SDKs
Start building in 5 minutes For everyone
Personal Supermemory
One memory across everything you use. What you teach one AI, every AI remembers.
Supermemory App
Control panel Claude · Cursor · Codex · OpenCode
AI plugins Chrome Extension
One-click save 10,000+ power users
Get Personal Supermemory
Legacy · A vector database
Stores chunks. Returns chunks. Each session starts from zero.
- Embeddings, namespaces, spaces
- Append-only; no contradiction logic
- Retrieval, not memory
Supermemory
Facts that evolve. Knowledge that merges, contradicts, and gets forgotten across every session.
- User profiles and ontology-aware graph
- Update, merge, contradict, infer
- One API: ingest, retrieve, remember
〉HOW IT WORKS
[3/9]
How it works
How it works.
Four primitives, one graph. Install, ingest, understand, retrieve. Then a fifth step that makes the previous four worth the effort.
01 / PLUG IN
Plug into your stack in minutes.
SDKs for every major language and model harness. Runs in every runtime, from edge functions to long-lived servers.
02 / INGEST
Bring in any type of data, from anywhere.
Supermemory automatically extracts the content for you, in a way that's optimized for retrieval and memory generation.




03 / UNDERSTAND
Entity model learns from raw context.
Our model resolves people, places, and concepts as they evolve over time.

04 / RETRIEVE
Memories form inside our custom graph.
Memory, RAG, and profiles live in the same queryable graph, not isolated vector blobs. One unified structure your agent traverses, not three systems you stitch together.
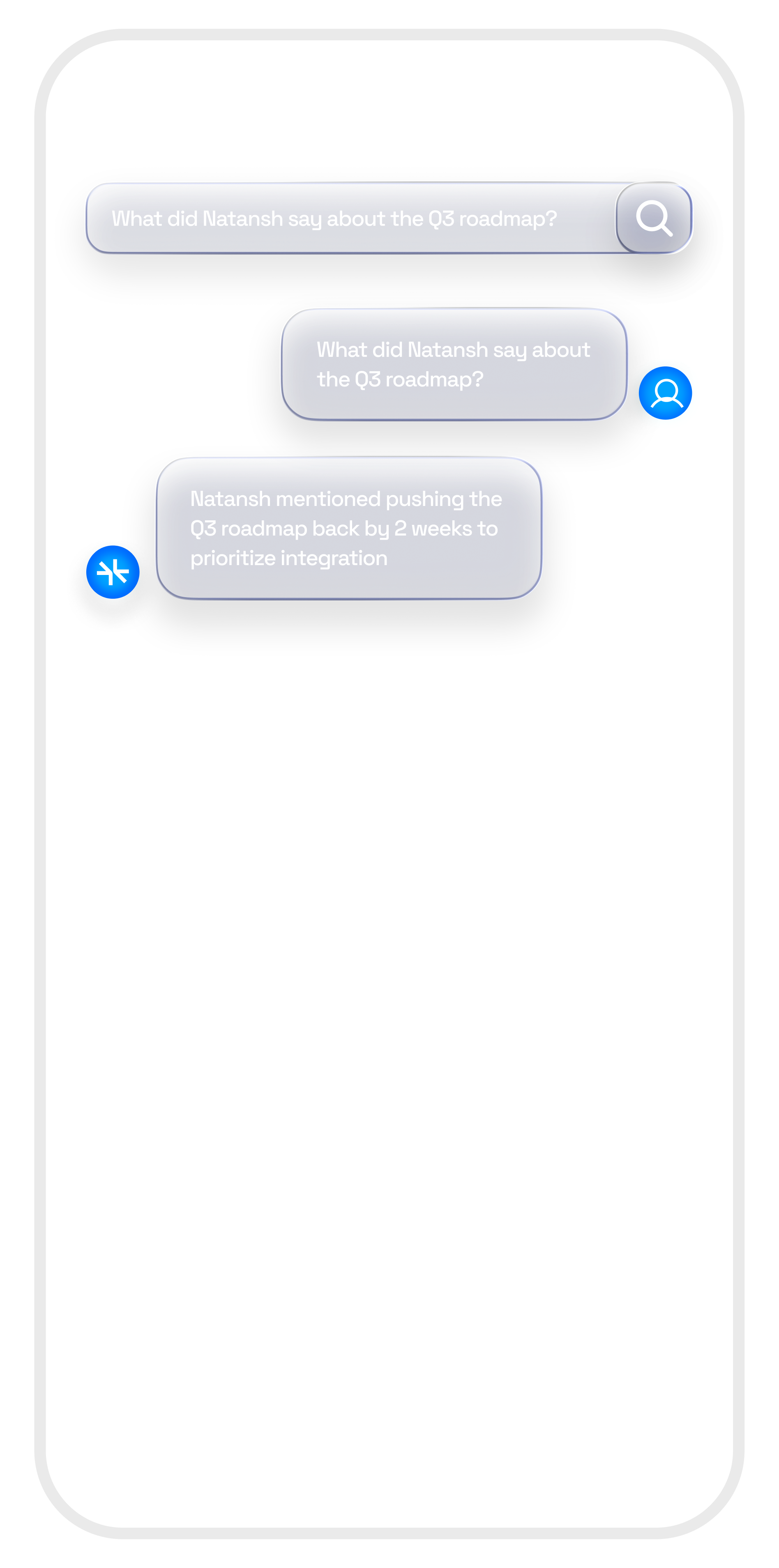
05 / Real-Time Traversal
Sub-300ms graph traversal, every request.
Steps 01–04 are the build. This is the payoff: your agent reaches into the graph at request time, not at training time.
〉BENCHMARKS
[4/9]
We don't think benchmarks tell the full story.
But we lead every major one anyway. SOTA on LongMemEval, LoCoMo, and ConvoMem.
We also built MemoryBench, an open eval platform for memory systems.
Recall quality,
like the human brain.
Recall time
Memories returned in milliseconds, 10× faster than Zep, 25× faster than Mem0.

Feature
Best Supermemory
Mem0
Zep
Memory Graph
Partial
User Profiles
Document Retrieval
Connectors
Document Extractors
Sub-300ms Latency
Self-hostable
Consumer Plugins
Open Eval Platform
〉USE CASES
[5/9]
Use cases
Best for latency, quality and cost. Or configurable for each use case.
AI assistants that remember your users.
Persistent context and reasoning memory. Chats, docs, and user data unified so assistants adapt over time.
In production at
 ppl.xyz
ppl.xyz  chatnow
chatnow
ppl.xyz chatnow Self-improving, for your users.
Ingest, sync, and retrieve from any source, so your agents always have the latest context, not stale snapshots.
In production at



Realtime knowledge for agents.
Keep your agents grounded in up-to-date facts from every source (docs, APIs, internal tools), synced and retrievable in milliseconds.
In production at


Used by engineers from the best teams.
Internal docs, wikis, and institutional knowledge: searchable and always current for every team member.
In production at


〉ENTERPRISE
[6/9]
Enterprise
Supermemory runs everywhere.
Supermemory runs on-prem, on your cloud, or fully air-gapped — with the same API, the same SLAs, and a paper trail your security team will actually read.
01 / ON PREMISES

In your data center.
Self-host on bare metal or your own Kubernetes. Zero data leaves your perimeter.
02 / YOUR CLOUD

In your VPC.
Deploy to AWS, GCP, or Azure inside your account. BYOC from day one.
03 / LOCAL

On your laptop.
Run the full stack on a workstation for offline dev, demos, or sensitive work.
SOC2
Compliant
SOC 2 Certified
Independent audit confirming that we safeguard your data with the highest security standards.
GDPR
GDPR Compliant
Compliant with EU data protection, ensuring your personal information is handled with care and transparency.
〉TESTIMONIALS
[7/9]
Testimonials
“We just ditched RAG completely and went memory only through Supermemory.”
Reduced avg response time from 40s → 12s. Using about 40–50% fewer tokens. Just memory & near realtime web-search even for volatile information.
Memory vs RAG
Latency (seconds)
“Tried almost everything — structured memory files, qmd etc. The only thing that works reliably is Supermemory.”
Not facing any memory issues after setting it up.
“Supermemory let us scale usage without losing the thread of every conversation.”
Max Peters, Founder 
〉PRICING
[8/9]
Simple pricing, by usage.
Pay only for what you use. Every plan comes with monthly credits, with no surprise bills and no upgrade walls.
Free
For builders tinkering, prototypes and side projects.
- Hermes Plugin
- Supermemory MCP
- Community support
Pro
Most pickedFor small teams and plugin power-users.
- Unlimited storage
- Unlimited users
- Auto top-up available
- Google Drive, Notion & OneDrive connectors
- 2 teammates included
- OpenClaw, Claude Code and other plugins
- Email support
Max
Most pickedMore headroom for developers who need it.
- Unlimited storage
- Unlimited users
- Gmail & Granola connectors (+ Pro)
- Auto top-up available
- OpenClaw, Claude Code and other plugins
- Priority support
Scale
For teams running production workloads.
- Unlimited storage
- Unlimited users
- Up to 10 teammates
- All connectors (Gmail, GitHub, S3, Web Crawler + Pro)
- Auto top-up + spend caps
- Priority support
- SOC 2 · HIPAA BAA
- Self-hosted option
〉FAQ
[9/9]
The fine print, in plain English.
-
Every plan comes with a monthly dollar balance. Each API call, storing memories, searching, indexing, draws from that balance at the rates listed above.
When the balance runs out, you can top up or auto top-up to keep going. No surprise bills at the end of the month.
-
SM tokens are the unique tokens Supermemory actually ingests and embeds; repeats and unchanged content don't get billed again. Effectively a 100% discount on what a normal prompt cache would re-charge you for.
Plain text is $0.005 per 1K SM tokens; rich content (PDFs, audio, video) is $0.010 per 1K because it needs heavier extraction.
PLAIN TEXT $0.005 / 1KRICH CONTENT $0.010 / 1K -
Nothing, you're not billed again. Supermemory deduplicates at the token level, so re-uploading a doc, syncing a connector, or pushing the same conversation history won't redraw from your balance.
Only net-new content counts as SM tokens. This is why production agents that loop over the same context end up an order of magnitude cheaper here than with a typical vector DB.
-
Subscription credits reset monthly. Top-up credits you purchase in advance never expire, they sit in your balance until you use them.
-
On Free, you'll be paused; pay-as-you-go isn't available on Free, so you'll need to upgrade to Pro or Scale to keep going.
On Pro and Scale, auto top-up kicks in to keep your app running. You can set hard spend caps on Scale to prevent runaway usage.
-
Self-hosted deployments are available on Scale and Enterprise. Enterprise additionally supports fully air-gapped deployments (LLM inference may be the only outbound dependency, unless GPUs are available).
-
Yes. Qualifying early-stage startups and academic research teams get up to $2,000 in credits, dedicated support, and 3 months to build. Apply via the Startup Program link above.
Still something on your mind?
Your Agent Second Brain Workflow needs it’s Supermemory
Start Building TOTAL MEMORIES SAVED 1,505,650,017