
Incident Report: October 18, 2025 Service Degradation


Summary
On October 18, between 1:17 PM and 1:45 PM PDT, we experienced service degradation that resulted in elevated API response times and some timeouts. This happened when two enterprise customers started major data backfills simultaneously— while we'd planned for one, the second caught us by surprise. The combination overwhelmed our database and triggered cascading retry issues that took about 30 minutes to fully resolve.
Here's what happened, how we fixed it, and what we're doing to make sure your data operations scale smoothly going forward.
What Happened
1:05 PM - Concurrent Large-Scale Imports Begin
Two of our enterprise customers started backfilling hundreds of millions of tokens at the same time. We'd worked with one customer to prepare for their import, but we didn't have visibility into the second one starting. Our database resources, which we thought were generously provisioned, hit their limits faster than expected.
1:15 PM - Database Saturation
CPU and memory utilization spiked rapidly. Query latency jumped, and some requests started timing out. We immediately began diagnosing the issue and preparing to scale.
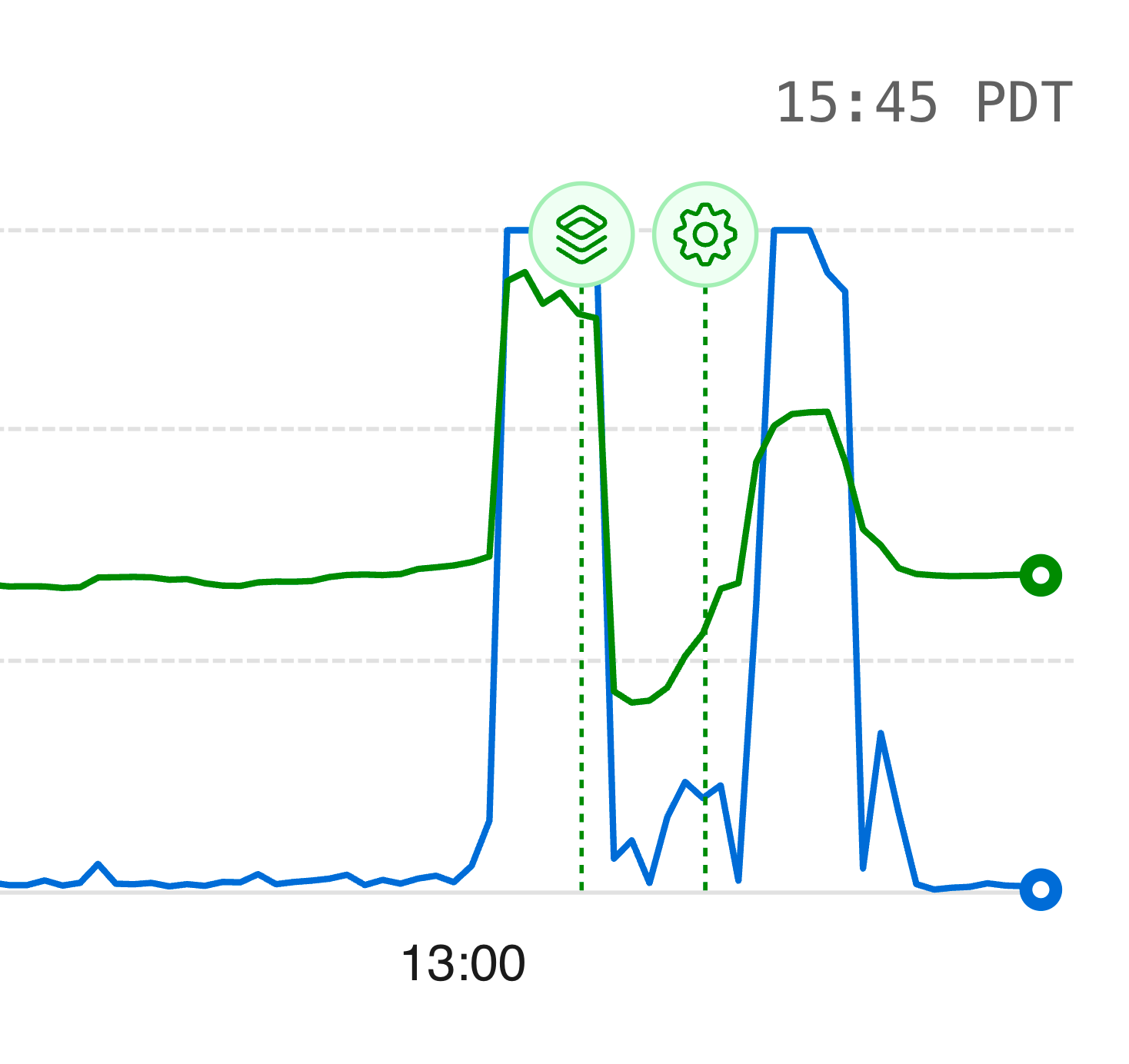
1:30 PM - Emergency Infrastructure Upgrade
We doubled our database resources—both CPU and RAM—and asked both customers to temporarily pause their imports while the upgrade completed. We are thankful to Planetscale for the observability that their dashboard provided, along with an option to upgrade even under load.
1:30-2:00 PM - The Retry Cascade
This is where things got interesting from an engineering perspective, and it taught us a lot:
Workflow Retry Amplification
We use Cloudflare Workflows to handle large bursts of ingestion requests asynchronously. It's a really architecture that normally handles spikes beautifully, as we have had almost 100% uptime since launch.
But when the database started rejecting queries, the automatic retry logic created a feedback loop: failed queries triggered retries, which added more load, causing more failures, triggering more retries. This kept our CPU elevated for about 15 minutes even after we'd upgraded the hardware.
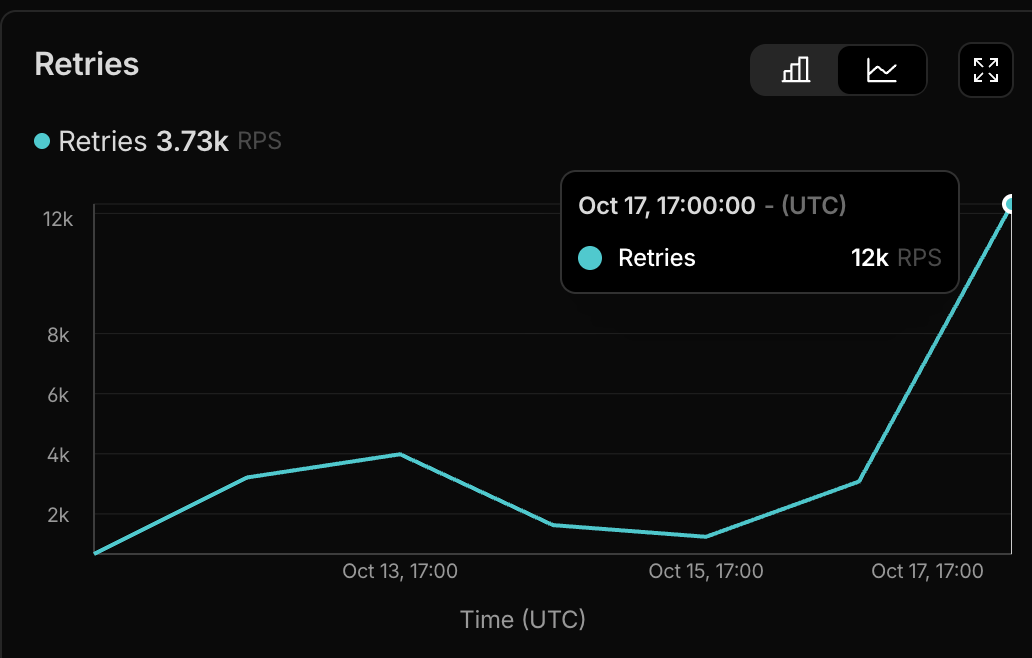
Queue Prioritization
We serve tens thousands of developers on our free tier alongside enterprise customers. We hadn't yet implemented priority-based workflow execution, so when we hit Cloudflare's parallel execution limit, enterprise requests ended up queued behind free-tier operations. The retry cascade made this worse—thousands of retrying workflows from the backfills were competing for execution slots.
Our API design contributed to the confusion. We weren't providing early feedback about queue status, so from a customer's perspective, it looked like requests were failing rather than queuing (even though the response code was 200 success). One customer understandably tried restarting their import, not knowing their original requests were already in the queue waiting to process.
Unfortunately because of the elevated requests, even though the workflows were running and retrying, the dashboard became a bottleneck, preventing us from seeing the full picture.
However we had experienced this before and simply used a script to find the number of running and retrying workflows.
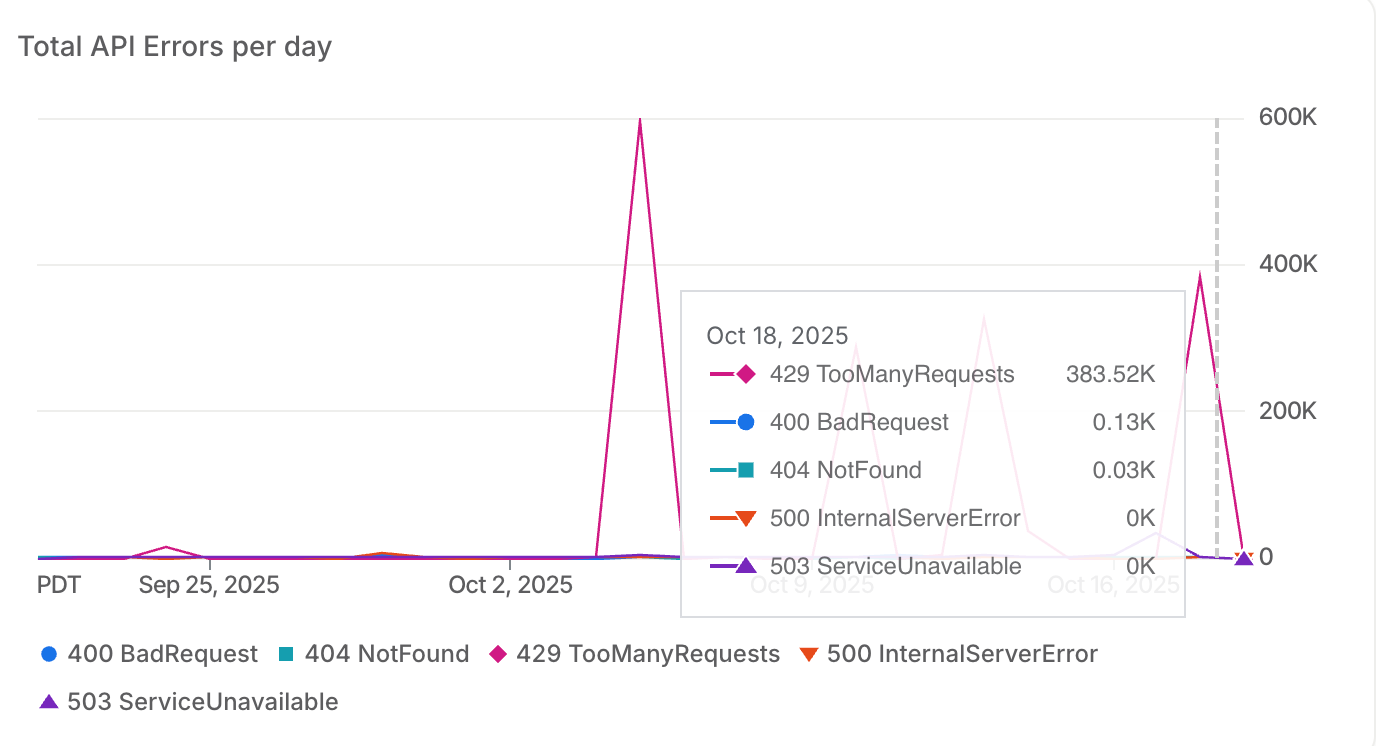
Third-Party Rate Limits
The retry volume included calls to Google's embedding API. We hit their rate limits, which added another layer of queuing to our system. Everything that could back up, did.
2:10 PM - Resolution
The database upgrade finished, and we coordinated with our customers to restart their imports. But here's what we learned about cascading retries: all the queued workflows fired simultaneously, creating about 4x the original request volume. The upgraded database immediately saturated again.
At this point, we made a judgment call. We killed all running workflows to break the retry cycle completely. Once the database stabilized, we manually reprocessed every pending request at half the original rate, ensuring everything completed successfully without impacting service.
Full resolution by 2:45 PM. Zero data loss.
What Worked Well
Before we get into what we're fixing, it's worth talking about what held up under pressure:
The System Stayed Up
Most API requests continued succeeding throughout the incident—they just took longer. We saw elevated latency, not widespread failures. Our status page didn't even flag this initially because success rates stayed high. The architecture degraded gracefully rather than falling over.
Serious Throughput Under Stress
At peak load, we were processing 2,800 requests per second. While everything was struggling. That's the kind of throughput that proves the fundamental architecture is solid.
Immediate Team Response
The entire engineering team was online when this started. We jumped on it within minutes, coordinated the response, and stayed on it until everything was resolved.
Data Integrity
The asynchronous workflow design meant requests queued instead of getting dropped. Not ideal for latency, but it meant zero data loss. Every request eventually processed successfully.
We Kept You Informed
We maintained direct communication with affected customers throughout, providing updates and coordinating actions in real-time.
Infrastructure That Scales
We doubled database resources mid-incident and it worked. That kind of elasticity is exactly what you need when things go sideways.
Our infrastructure had no bottlenecks in scaling, except for poor planning on our side.
Why We're Sharing This
Transparency matters, especially when you're trusting us with your data infrastructure. We could've written a vague "we experienced some latency" post, but that doesn't help you understand our engineering practices or how we handle pressure.
This incident revealed gaps in our workflow prioritization and coordination processes. It also demonstrated something important: our architecture handled 2,800 requests per second at peak load, the team responded immediately, and we maintained data integrity throughout. Most requests succeeded—they just took longer than they should have.
What We've Fixed
We moved fast on this. Some of these improvements went live the same day.
Enterprise Priority Execution (Live Now)
In the next one hour, we've implemented dedicated workflow resources for paid customers. Your operations are now isolated from free-tier traffic. If we see a spike in free-tier usage, it won't impact your performance. This went into production immediately after the incident.
Import Coordination Process
For large-scale data migrations, we now have a formal coordination process:
- Capacity planning sessions before major imports
- Scheduled import windows so we can ensure resources are available and multiple large imports don't conflict
- Temporary rate limit adjustments that we coordinate in advance
- Dedicated monitoring with an engineer watching during major data operations
If you're planning a significant backfill or migration, we want to know about it. Not because we need to "approve" it, but because we can make sure it goes smoothly.
Real-Time API Feedback
Our ingestion endpoint now provides immediate feedback:
- Instant validation on document format and structure
- Queue depth and estimated processing time in responses
- Clear distinction between "this request is invalid" and "this request is queued"
- No more silent failures that only appear in logs
You'll know immediately whether your data is being processed or if something needs adjustment.
Intelligent Retry Logic
We've implemented circuit breakers and exponential backoff in our retry logic. If a downstream service is struggling, we back off gracefully instead of amplifying the problem. This prevents the retry cascade we experienced. This was an easy fix, as a part of our migration to Effect and our use of Workflow and other Cloudflare resources.
What This Means for You
If you're currently a customer: Your operations now have dedicated priority execution. Large imports won't be impacted by platform-wide traffic, and we have better visibility to coordinate with you on major data operations.
If you're evaluating Supermemory: This incident is exactly the kind of stress test that reveals how a platform handles pressure. Our architecture processed nearly 3,000 requests per second during the incident. The team was online immediately. We maintained data integrity throughout. And we implemented meaningful improvements within hours, not weeks.
We're at a scale where these challenges emerge, and we're building the infrastructure to handle them properly. The improvements we've made don't just prevent this specific incident—they make the platform more robust for the kind of enterprise workloads we're designed to support.
Moving Forward
We know reliability is non-negotiable when you're building on top of our infrastructure. This incident happened, we handled it, and we're better for it.
If you're planning large-scale data operations or have questions about capacity, reach out. We'd rather coordinate with you proactively than discover your import when it starts.
We build in public, we share what goes wrong, and we fix it quickly. It's a part of our culture here at Supermemory.