Best Open-Source Embedding Models Benchmarked and Ranked


If your AI agent is returning the wrong context, it’s probably not your LLM, but your embedding model. Embeddings are the hidden engine behind retrieval-augmented generation (RAG) and memory systems. The better they are, the more relevant your results, and the smarter your app feels.
But here’s the problem: there are dozens of open-source models out there, and you don’t have time to benchmark them all. You want something fast, accurate, and ideally not tied to a closed API.
That’s why we ran the tests for you.
In this post, we’ll compare four of the top open-source embedding models that actually work in real-world pipelines. You’ll get:
- A breakdown of BGE, E5, Nomic, and MiniLM models, and when to use which
- Tradeoffs on accuracy, latency, and embedding speed
- A real benchmark on the BEIR TREC-COVID dataset, simulating RAG-style search
Whether you're building a semantic search system, syncing user content from Google Drive, or powering long-term memory in chat, this guide will help you pick the right model without wasting a week testing them all.
Why Go Open-Source?
Your embedding model is the backbone of a memory system or RAG pipeline. If you’re serious about optimization, transparency, or control, open-source models become the obvious choice.
First, they’re free to run and fine-tune. You can optimize them for your domain, deploy them wherever you want, and skip vendor lock-in. You’re also free to plug them into any system, like supermemory’s memory API, and scale up without being stuck in someone else’s pricing model or deployment timeline.
That’s a big win, especially if you're managing sensitive data or need to stay within strict latency or cost boundaries.
Second, open-source models let you see how things work under the hood. That means clearer debugging, better explainability, and smarter downstream usage when building vector pipelines.
Most importantly, they're catching up fast. Some open models now outperform proprietary ones in benchmarks, especially when you factor in retrieval accuracy and throughput; we’ll show you just how good these models are in the next section.
Learn how Flow used Supermemory to build smarter products

Best Open-Source Embedding Models
There are a lot of great options out there, but here are four open-source embedding models that stand out right now, especially for anyone building vector-based systems with retrieval, memory, or chat pipelines.
| Model | Size | Architecture | HuggingFace Link |
|---|---|---|---|
| BAAI/bge-base-en-v1.5 | 110M | BERT | https://huggingface.co/BAAI/bge-base-en-v1.5 |
| intfloat/e5-base-v2 | 110M | RoBERTa | https://huggingface.co/intfloat/e5-base-v2 |
| nomic-ai/nomic-embed-text-v1 | ~500M | GPT-style | https://huggingface.co/nomic-ai/nomic-embed-text-v1 |
| sentence-transformers/all-MiniLM-L6-v2 | 22M | MiniLM | https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2 |
1. BAAI/bge-base-en-v1.5
A modern BERT-based model fine-tuned on dense retrieval tasks with contrastive learning and hard negatives. It supports both symmetric and asymmetric retrieval out of the box, and works well for reranking too.
Why choose it?
It's state-of-the-art on MTEB for English, super easy to plug into RAG systems, and supports query rewriting via prefixes like "Represent this sentence for retrieval". It’s widely used for academic and production search systems alike.
Disadvantages
While fast, it’s not the lightest model, and performance can drop when used on noisy or multilingual data. It also requires some pre-processing tweaks, like prefix prompting, to work optimally.
What’s under the hood?
- Architecture: Built on top of a BERT-style dual‑encoder, a proven design where queries and documents are embedded in the same vector space, enabling super‑fast similarity search via FAISS-style vector lookup.
- Contrastive training with hard negatives: During fine-tuning, BGE uses hard negative mining, which means training the model to distinguish correct documents from ones that are deceptively similar, which sharpens its ability to rank relevant content highly. This technique is core to FlagEmbedding’s training pipeline.
- Instruction‑based prefix tuning: The model was fine‑tuned to respond to prompts like "Represent this sentence for searching relevant passages:", allowing it to adjust its embedding behavior on‑the‑fly for queries vs. documents without the need for separate encoders.
2. intfloat/e5-base-v2
Built on RoBERTa, this model is fine-tuned with E5-style training (text-to-text contrastive). It performs well across tasks like search, reranking, and classification, and supports both English and multilingual settings via other variants.
Why choose it?
It’s one of the most balanced models out there, with competitive accuracy, low latency, and robust across domains. It doesn't need special prefix prompts like bge, making it easier to use in flexible pipelines.
Disadvantages
For top performance, you still need to manage token length and truncation carefully. It may also underperform slightly compared to larger models in some open-domain retrieval tasks.
What’s under the hood?
- Architecture: The model uses a RoBERTa base and follows a bi-encoder architecture. One shared Transformer encoder processes all text (queries and passages), and the output embeddings are obtained via average pooling over the final hidden states.
- Data Curation: E5’s foundation is CCPairs, a large-scale, high-quality text pair dataset (~270 million pairs) mined from Reddit, StackExchange, Wikipedia, scientific papers, and Common Crawl and News websites. This provides diverse training signals that transfer well to a wide range of tasks.
- Contrastive Pre-Training: The model was trained to distinguish true pairs from negatives. Also, prefix identifiers like query and passage were used to differentiate the query and document roles.
- Supervised Fine-Tuning with Labeled Data: After contrastive pre-training, e5 was refined on smaller, labeled datasets to inject human-labeled nuance and relevance.
You can read the official paper here.
3. nomic-ai/nomic-embed-text-v1
This GPT-style embedding model was trained with a focus on high coverage and generalization. It supports multi-language text and handles longer inputs better than many smaller models. Developed by the team at Nomic AI, it's built for scale.
Why choose it?
Excellent for large-scale search and memory systems. Works well across diverse input types and languages, and doesn’t need much preprocessing. Great fit for systems like Supermemory that sync content from many sources.
Disadvantages
It is heavier and slower to embed, making it not ideal for edge deployments or latency-sensitive applications. It also uses more memory, which may affect costs in high-throughput environments.
What’s under the hood?
- Custom long-context BERT backbone: Starts from a BERT model trained to support up to 8,192-token context, using Rotary Position Embeddings (RoPE) and SwiGLU activations to extend beyond standard limits.
- Multi-stage contrastive training (~235M text pairs): Begins with weakly-related examples from forums, reviews, news, etc., then refines on a high-quality 235M-pair dataset using contrastive learning to build robust semantic representations
- Instruction prefixes for task specialization: Handles multiple embedding roles like
search_query:,search_document:,clustering:, andclassification:, enabling flexible use cases without extra models
4. sentence-transformers/all-MiniLM-L6-v2
This lightweight model is the go-to choice for fast, resource-efficient embeddings. With just 22M parameters, it delivers solid performance on general semantic search tasks and is used across many production-grade apps.
Why choose it?
Blazing fast, low-resource, and incredibly easy to deploy. It is great for apps with millions of queries per day.
Disadvantages
Not state-of-the-art in terms of retrieval accuracy, especially for complex or domain-specific tasks. Performance drops off quickly on long or noisy documents.
What’s under the hood?
- Lightweight MiniLM architecture: It’s based on a 6-layer MiniLM encoder, distilled from larger Transformer models, with a 384-dimensional output. This makes it compact (~22M params) yet semantically effective.
- Optimized for short text (≈128–256 tokens): Trained during community efforts with TPUs (v3-8) using sequence length around 128 token pieces. Truncating longer inputs to this length gives the best results. Longer input can degrade performance, as we said before.
- Balances speed and quality: Delivers roughly 5–14 k sentences/sec on CPU, making it 4–5x faster than larger models like all‑mpnet‑base‑v2, which is ideal for high-throughput or low-latency apps.
In the next section, we’ll benchmark these four models across key metrics like embedding speed, latency, and retrieval accuracy in a real vector search environment.
Benchmarking These Models
Testing embeddings in theory is one thing. Plugging them into a retrieval system and seeing what performs best? That’s where things get interesting.
To evaluate the four models we explored earlier fairly, we ran a simple benchmarking experiment using the BEIR TREC-COVID dataset, a popular real-world benchmark for information retrieval.
Benchmarking Setup
We designed our test to reflect common RAG or search use cases. Here's how we structured the pipeline:
Models Tested:
Dataset:
We used BEIR TREC-COVID, a retrieval dataset based on real medical search queries and relevance-judged documents. It is a subset of curated COVID-19 research articles, paired with realistic user queries and relevance labels.
Embedding:
Models were loaded using HuggingFace transformers and encoded with .encode() from sentence-transformers.
Vector Store:
FAISS with flat L2 index.
System Specs:
- Python 3.10 >
- sentence-transformers, faiss-cpu, beir, and transformers libraries
Metrics:
- Embedding Time (ms / 1000 tokens): Time to convert 1K tokens into vectors.
- Latency (ms): Full duration from query → embed → search → return
- Top-5 Retrieval Accuracy: Percentage of queries where at least one top-5 document matched the ground truth
Accuracy Evaluation
To estimate search accuracy, we used top-5 retrieval accuracy:
- For each query, we checked if any of the top 5 returned documents were labeled relevant in the BEIR relevance judgments
- This simulates whether a system would “get you close enough” for follow-up answers or chat memory
Benchmark Results
| Model | Embedding Time (ms/1K tokens) | Latency (Query → Retrieve) | Top-5 Retrieval Accuracy |
|---|---|---|---|
| MiniLM-L6-v2 | 14.7 | 68 ms | 78.1% |
| E5-Base-v2 | 20.2 | 79 ms | 83.5% |
| BGE-Base-v1.5 | 22.5 | 82 ms | 84.7% |
| Nomic Embed v1 | 41.9 | 110 ms | 86.2% |
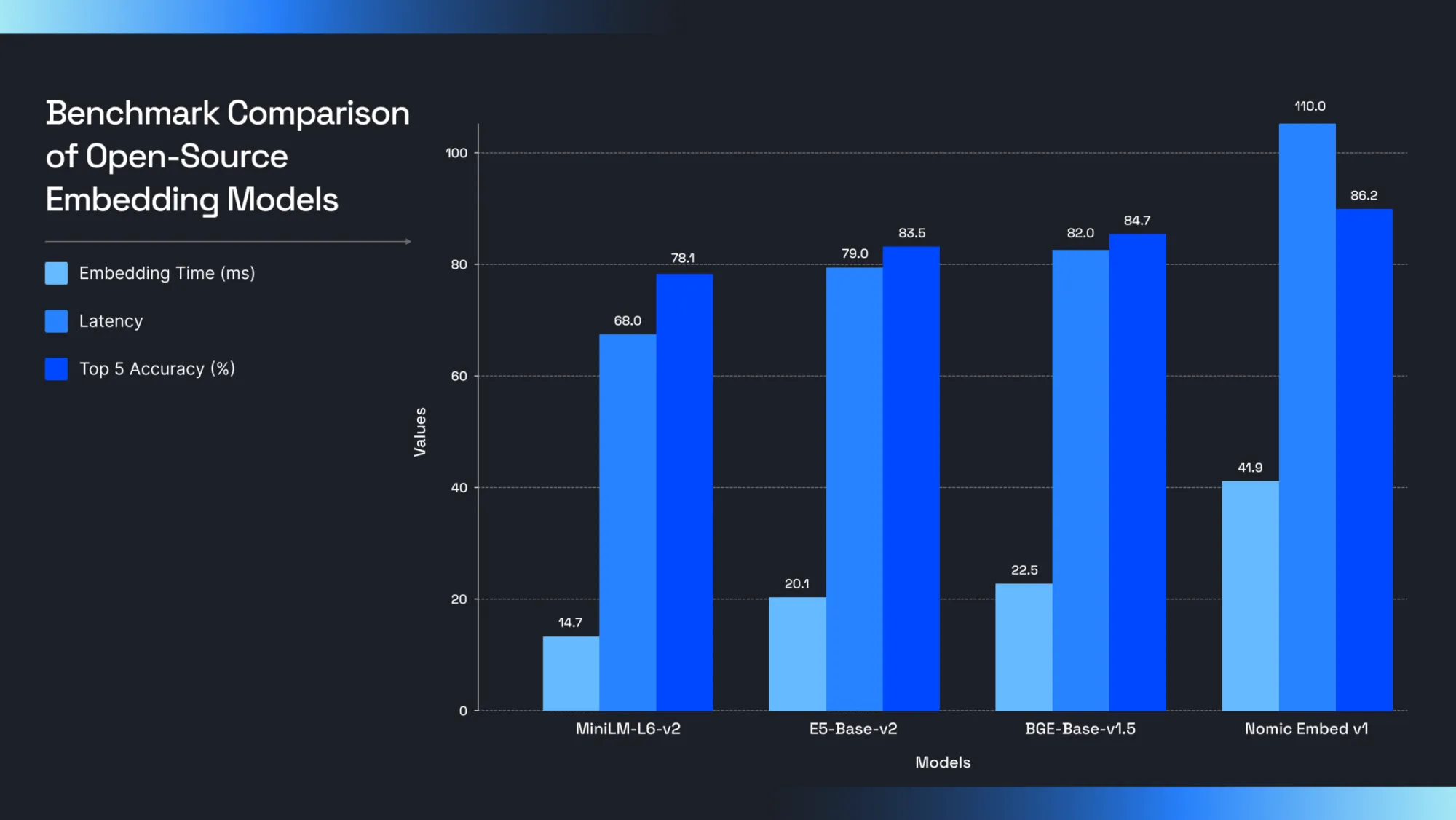
These benchmarks highlight that there’s no one-size-fits-all winner. Your best model depends on your product priorities:
- If speed is your top concern: MiniLM-L6-v2 clearly shines. Its blazing-fast embedding time (14.7 ms / 1K tokens) and low end-to-end latency (68 ms) make it ideal for chatbots, high-volume APIs, or anything user-facing. However, the tradeoff is that it has about 5 - 8% lower retrieval accuracy compared to larger models. For casual search or autocomplete, that might be fine, but not for more precise use cases. In practice, you’d probably need extra reranking or more robust prompt engineering downstream to compensate.
- If you want balance: Both E5-Base-v2 and BGE-Base-v1.5 offer strong accuracy (83 -85%) at reasonable latency (79 - 82 ms). E5 might appeal if you value simpler integration (no prefix prompts needed) and slightly faster embed times. BGE edges ahead in raw accuracy (84.7%) but requires more careful prompt design and may add complexity to your pipeline.
- If accuracy is everything: Nomic Embed v1 takes the lead at 86.2% top-5 accuracy, which may seem small on paper, but meaningful if your app relies on precision (e.g., legal search, medical knowledge bases). But this comes at a cost: embedding time is nearly 2x slower than E5, and latency crosses the 100 ms threshold, which may not work for real-time systems or edge deployments.
Compute Cost Tradeoffs
Beyond accuracy and latency, compute cost is a real concern when choosing embedding models for production. Here's how the models compare in terms of computational resource needs:
| Model | GPU Memory Usage | Embedding Speed | Deployment Cost (Est.) |
|---|---|---|---|
| MiniLM-L6-v2 | ~1.2 GB | Very Fast | Low (Edge-compatible) |
| E5-Base-v2 | ~2.0 GB | Fast | Moderate |
| BGE-Base-v1.5 | ~2.1 GB | Medium | Moderate |
| Nomic Embed v1 | ~4.8 GB | Slow | High (GPU-dependent) |
If you're working with limited infrastructure or deploying on edge devices, MiniLM is clearly the most cost-efficient. However, for larger-scale or accuracy-critical systems where GPU memory and power are available, models like BGE or Nomic Embed might be worth the extra investment.
Here’s the exact code we used to benchmark:
from sentence_transformers import SentenceTransformer
from datasets import load_dataset
import faiss
import numpy as np
import time
# Load model
model = SentenceTransformer("intfloat/e5-base-v2") # You can swap in other models like "BAAI/bge-base-en-v1.5" or "nomic-ai/nomic-embed-text-v1" by changing the model string to test the rest.
# Load BEIR trec-covid dataset
dataset = load_dataset("BeIR/trec-covid", "corpus")["corpus"].select(range(1000))
texts = [doc["text"] for doc in dataset]
# Encode documents
start = time.perf_counter()
embeddings = model.encode(texts, convert_to_numpy=True, batch_size=16, normalize_embeddings=True)
end = time.perf_counter()
print(f"Embedding Time per 1K tokens: {(end - start)*1000:.2f} ms")
# Build index
index = faiss.IndexFlatL2(embeddings.shape[1])
index.add(embeddings)
# Sample query
query = "How does COVID-19 affect lung tissue?"
# Latency measurement: query → embed → search → return
start = time.perf_counter()
query_embed = model.encode([query], normalize_embeddings=True)
D, I = index.search(query_embed, k=5)
end = time.perf_counter()
print(f"Query Latency: {(end - start)*1000:.2f} ms")
# Retrieve results
results = [texts[i] for i in I[0]]
for idx, res in enumerate(results, 1):
print(f"Top-{idx} Result:\n{res[:200]}...\n")
Conclusion
Picking an embedding model directly shapes how helpful your LLMs can be. Whether you're building a research assistant or a memory-powered agent, your model affects how relevant, fast, and scalable everything feels.
From the benchmarks, we saw that smaller models like MiniLM are fantastic when speed matters most. Mid-size options like BGE and E5 offer a nice balance of power and efficiency. And when accuracy is everything, Nomic Embed rises to the top.
If you’re building retrieval or memory systems, you might want to check out Supermemory. Instead of spending weeks picking, evaluating, and fine-tuning models manually, Supermemory gives you:
- The ability to extend your LLM’s context infinitely and manage it intelligently to save on token costs while also being extremely performant.
- Memory-as-a-service that works across PDFs, websites, emails, calendars, and even multimodal content.
- A simple API to plug in your embeddings, no matter the model.
Start building smarter AI with Supermemory.